
データ品質の5つの分類と品質管理プロセス
風音屋(@kazaneya_PR)アドバイザーの笹川です。 本稿は datatech-jp Advent Calendar 2023 14日目の記事です。
本稿では、データ活用において重要な概念である「データ品質」の分類と管理プロセスについて紹介します。
- 関係者がデータ品質の全体像を把握できる分類方法(「データ品質の5つの分類」)
- 5つの分類に沿ってデータ品質担保に向けた活動(テスト / 監視など)を整理するためのテンプレート
- データ品質の現状を把握し、継続的に改善するためのプロセス
一方、改善方法の具体例については、個別の事例やツールに強く依存する内容となるので、本稿では扱わないこととします。
注意事項
本稿で紹介する「データ品質の分類方法」を風音屋メンバー以外が使う場合、必ず引用元を明記してください。
記事の想定利用者
本稿の読者として以下のようなロールの方を想定しています:
- データを利用するアナリストや、企画、戦略立案などの担当者(データユーザー)
- データ基盤を運用するチームのエンジニア(データスチュワード / データエンジニア)
- データソースとなるDBやログなどを保持するサービスの担当エンジニア(データオーナー)
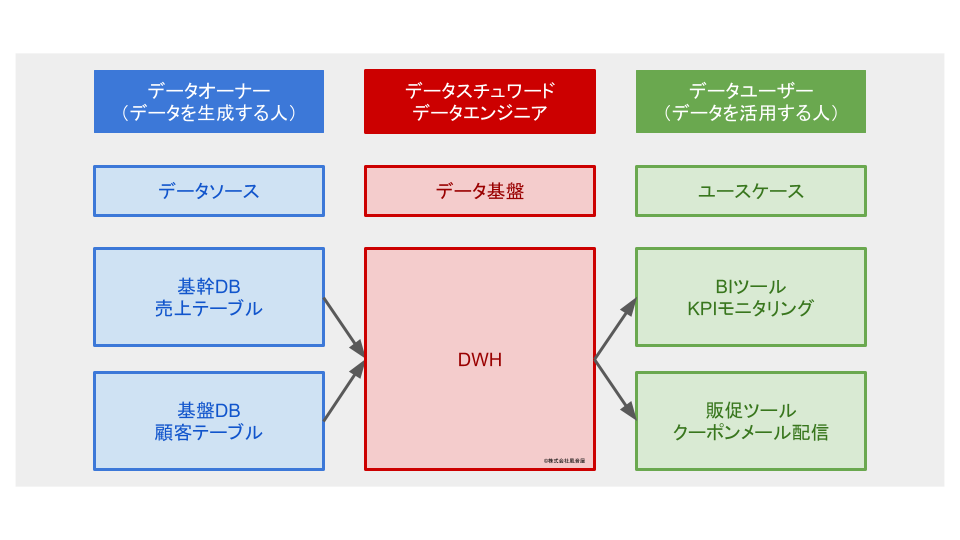
上記の1-3に挙げたロールは、データを活用する際に相互に協力するべきロールです。 「データ分析者の要望に応じて新たにログを取得する」「ログ欠損を受け入れてデータの使い方を工夫する」など、ステークホルダーがお互いに歩み寄って、データ品質の落とし所を決めていきます。 後ほど説明するデータ品質ドキュメントを作成 / 運用することで、ロール間の協力をスムーズにし、データ活用がより促進される効果が期待できます。
データ品質分類の定義
以下では、データ品質向上のためのモチベーションと、風音屋が整理した「5つの品質分類」を説明します。
データ品質とは何か?
データ品質とは、データを意思決定に使える状態になっているかという点を、様々な角度から評価したものです。 本稿では、データと、そのメタデータを対象とし、データ品質を評価する方法と、評価した品質を管理する方法について説明します。
なぜデータ品質が重要なのか?
データ品質を守り向上していくことは重要です。 Garbage in, garbage out(ゴミを入れてもゴミしか出てこない)と称されるように、データ品質が低いと、データの活用によって得られるであろう便益にマイナスの影響が発生することがあります。 具体的には、
- 個人情報の漏洩
- 前処理などの複雑化により開発保守工数の増加
- 誤った分析結果に基づく意思決定の発生
- レコメンド精度の低下による営業損失
などがあります。 反対に、高いデータ品質は、それを利用するユーザ / 施策に対して広くプラスの影響を与え、さらなるデータ利用の促進、サービスの拡大が期待できます。
ただし、過剰品質には注意です。 既に一定の品質を満たしている場合には、それ以上の品質向上を積極的に「諦める」ことを検討する必要があります。 具体的には、データの連携頻度について、マスタデータなど更新頻度が比較的少ないデータの連携頻度は、多くとも日次程度で十分と考えられます。 これをリアルタイム連携にすることは、データの利用者にとっての利益はそれほど向上しないにもかかわらず、連携ジョブの運用難易度は大幅に上がってしまうため適切ではないと思われます。
データ品質の分類
本節では、風音屋が独自に分類した「5つのデータ品質」について説明します。 以下の表に示す品質分類は、ISO2501を元にデジタル庁がまとめたデータ品質管理ガイドブック(以下「ガイドブック」とする)の定める15の品質分類に、DMBOKに記載されている「移植性」「一意性」を加えた上で、5つにまとめ直したものです。 また表には、それぞれの分類が、ガイドブックの分類のどの要素を含むのかについても併せてまとめています。
| 分類 | 内容 | 分類が内包するガイドブックの要素 | |
|---|---|---|---|
| 1 | 追跡可能性 | 品質管理の土台となる証跡が担保されていること。データソース、生成ロジック、利用状況といった過去の事実を遡ることができること。 | 追跡可能性、信憑性 |
| 2 | 可用性 | 適切なシステムにデータが格納されていること。適切な頻度・時間でデータが連携され、適切なレスポンスタイムでデータを提供できること。トラブル時にはバックアップやシステム移行によって速やかに復旧できること。 | 最新性、可用性、回復性、移植性 |
| 3 | 正確性 | データの中身が現実を正確に反映していること。欠損 / 重複がなく格納されており、データの値、有効な値の列挙集合 (enum)、数値範囲などに収まっていること。 | 完全性、一意性、一貫性、有効性、精度 |
| 4 | アクセシビリティ | 適切な人 / 組織が、適切な範囲のデータにアクセスできること。 | アクセシビリティ、機密性 |
| 5 | ユーザビリティ | データが使いやすい状態になっていること。テーブルや個々のデータの意味がデータ利用者にとってわかりやすく説明されていること。 | 理解性、効率性、標準適合性 |
上記の5つの項目の関係を図示したものが以下の図です。
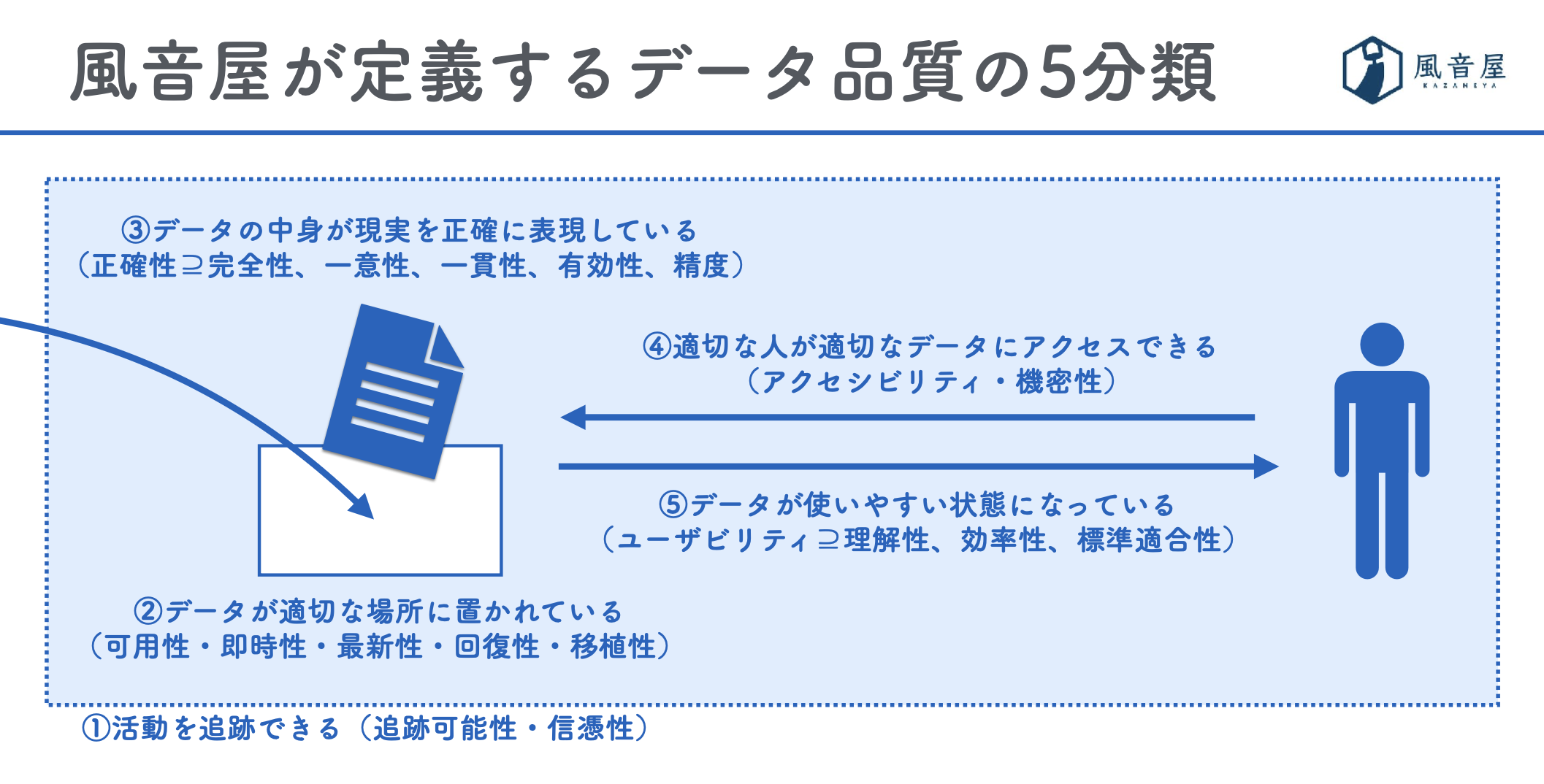
上記の5つの分類は、番号の小さい順に優先して整備していくことが重要です。 これは、ある分類はそれより番号が小さい分類に依存しているためです。 例えば、購買記録データに意図せず個人情報が含まれている(3の正確性が担保されていない)ケースでは、権限管理ルール(4のアクセシビリティ)を整備しても問題は解決せず、先にデータの中身を把握する必要があります。 改善の優先度に迷う場合には、番号が小さい分類から順に改善することを心に留めておくと良いでしょう。 また、前述の通りですが、品質向上とかかるコストのトレードオフに注意し、いきなり100点を目指さないことも同様に重要です。 一定以上の品質を担保した後は、2(可用性)よりも5(ユーザビリティ)を優先的に向上させるといった判断がなされることもあります。
正確性については、個々の要素について簡単にまとめておきます。テストや監視項目などで、細かい議論が発生することがあるためです。
| 構成する要素 | 内容 |
|---|---|
| 完全性 | データに欠損がないこと。レコードレベルの欠損だけでなく、必須カラムのnull値の混入なども含む。 |
| 一意性 | データに重複がないこと。レコードレベルの重複だけでなく、同じ人物の2重登録なども含む。 |
| 一貫性 | データ間に矛盾がないこと。データの結合時に紐づくべきデータが紐づかないなども一貫性に違反がある。 |
| 有効性 | データが、有効な値の列挙集合 (enum)、数値範囲などに収まっていること。 |
| 精度 | 有効桁数、許容誤差など「データの正確さの程度」がデータ間で揃っていること。それらが明示されていること。具体的には、当該カラムがdate型で十分なのか、timestamp型が必要なのかなど。 |
以降では、上記の分類を用いて、データ品質を評価し、その品質を管理 / 向上していくプロセスについて説明します。
データ品質分類の管理方法
先に定めたデータ品質分類に従って、実際のデータに対して、データ品質を評価し、それらを管理 / 向上していくことを考えます。 はじめに、データ品質の「管理プロセス」を定義し、その上で、データ品質の現状を定義に基づいて実際に管理する方法を紹介します。
データ品質管理プロセスの定義
ここでは、ISO8000 のdata quality managementをベースに、 データ品質の管理プロセスを、「個々のデータに対して次の手順を行うこと」、と定義します:
- 品質の基準や目標(満足させたい具体的な内容)を決定すること
- 1で設定した基準に対して、以下を決定すること
- 基準に適合していることをテストする方法
- 品質基準に適合していることを監視する方法
- 1の基準に違反している時について、以下を決定すること
- 基準の違反時に発生する不利益
- 基準の違反時の対応優先度
- 上記までで設定した項目に沿って、関係者間で協力してデータやシステムを継続的に改善していくこと
データ品質管理のためのドキュメントテンプレート
データ品質管理プロセスを実際に運用していくためには、データ品質のあるべき状態と対応方法を整理し、関係者間で合意することが重要です。 以下に、先に述べた5つのデータ品質分類に基づき、データ品質を管理するためのドキュメントテンプレートを示します。
| 品質分類 | 内容 | 検証方法 | 監視方法 | 分類違反時に発生する不利益 | 対応優先度 |
|---|---|---|---|---|---|
| 追跡可能性 | |||||
| 可用性 | |||||
| 正確性 | |||||
| アクセシビリティ | |||||
| ユーザビリティ |
各セルに埋めるべき内容については以下の通りです。
- 内容: 品質分類に基づき満たして欲しい具体的な項目を書きます
- 検証方法: データが内容に定めた項目に沿っているか検証する方法を書きます
- 監視方法: 内容に定めた項目が実現されているか日々確認する方法を書きます
- 分類違反時に起こる不利益: 分類を違反した際に何が起きるのか書きます
- 対応優先度: 分類を違反した際の対応の優先度を書きます
上記の内、「対応優先度」は特に運用において重要なので、次の節で詳しく説明します。
また、作成したドキュメントは何らかの方法で変更履歴を保存できると便利です。 筆者の個人的なおすすめは、ドキュメント自体をGitで管理し、変更の際にはpull requestを作成し、descriptionに変更理由を付記することです。 ドキュメントにchange logページを用意し、変更内容を記載していく方法もあります。
分類違反発生時の対応優先度
データ品質管理のみならず、優先度付けは、リソースが有限である限りにおいて逃げることはできない要素であり、先述の通り過剰な対応は利用者 / 運用者双方に悪い影響があります。 これを設定することで、特に運用サイドが、過度にリカバリ実施に追われるなどで疲弊することを防ぎ、適宜品質改善タスクに取り組めるようになります。 時間がない場合でも、必ず実施するようにしましょう。
以下では、具体例として、優先度を3つに分けることを考え、各レベルでの対応方法を示しています。 実際の運用では、担当メンバーの人数や習熟度、データ利用先タスクの重要度などに合わせて、各レベルの内容を随時検討すると良いでしょう。
| レベル | 内容 |
|---|---|
| 1 | 通常案件と並べて優先順位を検討し、それに応じて営業日対応 |
| 2 | 営業日に優先対応 |
| 3 | 深夜、土日祝日などにも発見次第、即時対応 |
データ品質管理プロセスを運用する方法
次にデータ品質管理を実際に運用する方法について説明します。
データ品質管理は、データの生成元のチームだけでなく、利用者も巻き込んで運用していくことが重要です。 その最初のステップとして、求めるデータ品質をまとめたドキュメントを作成した上で、関係者間で合意し運用するのがいいでしょう。 全ての関係者を巻き込んでドキュメントを作成するのが理想ですが、難しい場合は、はじめにデータマネジメント担当が叩き台を作ってしまうのもひとつの手です。 作成したドキュメントは、適宜問い合わせや、見直しのため、全員が参照可能な状態にしておきましょう。 具体的なデータ品質管理のフローとしては以下のようにするのが良いでしょう。
- 個別のデータごとに、データ品質管理の1(目標設定)〜3(違反時の不利益)までを整理する
- 定期的に関係者でタスクの棚卸しミーティングを実施し、目標や基準の見直し、継続改善のためのタスクアサインを進める
2のミーティングで話した内容は、品質の基準や目標を決めるための重要なインプットになります。議事録のような形式で良いので、記録しておくことをお勧めします。 目標の見直しやインシデントの対応方法に変更があった際には、品質ドキュメントを変更する(先述の変更履歴を追加する)とともに、議事録と相互リンクを記載しておくと良いでしょう。 また、このミーティングは、データの重要性や、開発フェーズに応じ適切な頻度で設定しましょう。
本筋とは外れますが、tipsとして、定例の会議は、月曜や、月末を避けて設定するのがおすすめです。 月曜は祝日が多くてキャンセルになりやすく、月末は28, 30, 31など日付が安定せず「今日は最終週なのか」が判別しにくいからです。
まとめ
本稿では、データ活用において重要な概念である「データ品質」の分類と管理プロセスについて紹介しました。 上記の方法を参考に、データ品質を継続的に改善し、本質的なデータ活用に注力できるようにしていきましょう。
本稿ではドキュメント作成の詳細までは説明しきれませんでした。品質管理の対象とするデータの選定方針、ドキュメントに記載する粒度、優先順位の付け方、ステークホルダー間での認識のすり合わせ方法といった内容については、またの機会にご紹介できればと思います。