
ディメンショナルモデリングでアクセス分析のファクトテーブルをどう設計するか
こんにちは、風音屋 データエンジニアの妹尾です。 この記事は、datatech-jp Advent Calendar 2023 15 日目の記事です。
ディメンショナルモデリングを採用する場合、アクセスログやGA4のファクトテーブルは、どのように設計すれば良いのでしょうか。 この疑問について風音屋でディスカッションをしました。 本記事では、ディスカッションした内容をご紹介します。
社内ディスカッションの様子
ディスカッションの様子

アドバイザーの皆様の協力もあり、課題を整理し、対応方針を洗い出すことができました。 @tvtg_24さん、@hanon52_さん、ありがとうございました!
背景と課題
「商品ページにアクセスしたユーザーのリストが欲しい」という要望があり、アクセスログやGA4のイベントデータでファクトテーブルを作成する場合、どのように設計するのが良いでしょうか。
要望に対して素直に設計していくのであれば、商品ページへのアクセスに絞ってファクトテーブルを作成すべきです。
しかし、今後「商品ページから購入ページへ遷移したユーザーのリストが欲しい」など、商品ページに閉じないサイト内回遊に関する分析の要望が出てくることは容易に想像できます。
これらを考慮した場合、アクセス分析のファクトテーブルはどのように設計すべきなのでしょうか。
方針ごとにメリット、デメリットを洗い出してみました。
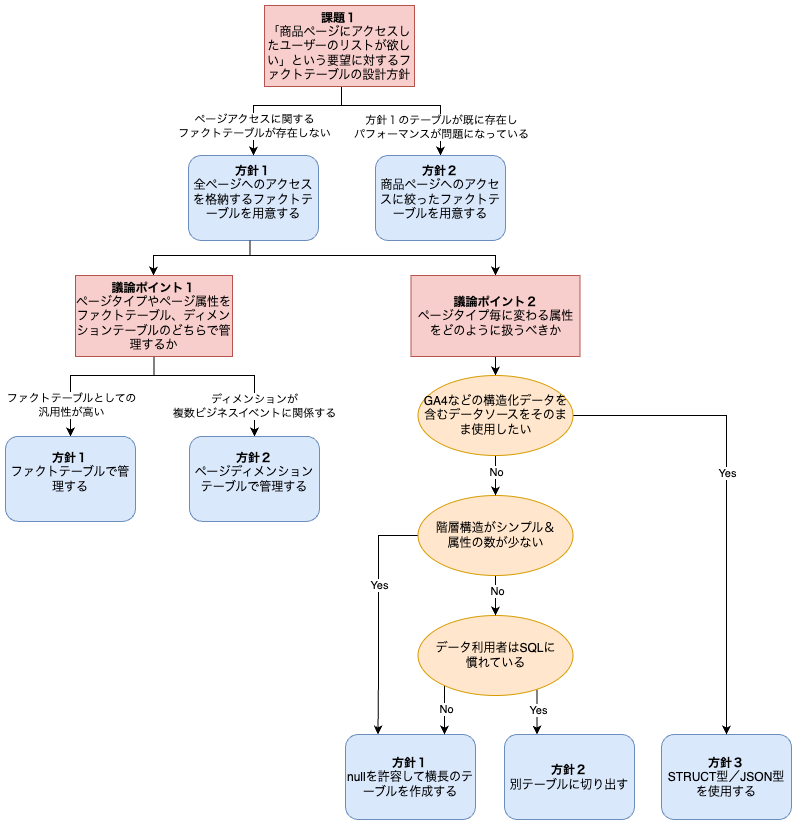
課題1:「商品ページにアクセスしたユーザーのリストが欲しい」という要望に対するファクトテーブルの設計方針
方針1:全ページへのアクセスを格納するファクトテーブルを用意する
| メリット | 説明 |
|---|---|
| ファクトテーブルとして汎用性が高い | 後から商品ページへのアクセスに絞って別のテーブルとして切り出すことも検討できる |
| 管理するテーブルの数が増えにくい | ページタイプが増えるたびに新たにファクトテーブルを作成する必要がない |
| デメリット | 説明 |
|---|---|
| データがわかりにくくなる | ページタイプによって紐づける属性が違うので、利用可能なタイプと属性の組み合わせが分かりにくくなる ページタイプが増えると属性も増える可能性があるので、横長のファクトテーブルになる ・商品ページには商品IDが必要 ・コンテンツページにはコンテンツIDが必要 ・検索ページには検索クエリが必要 |
| クエリパフォーマンスが低い | 全ページのアクセスデータを格納することによって、レコード数が増える |
方針2:商品ページへのアクセスに絞ったファクトテーブルを用意する
| メリット | 説明 |
|---|---|
| データがわかりやすい | 商品ページに紐づく属性しか持たないので、カラム数が少ない |
| クエリパフォーマンスが高い | 商品ページへのアクセスのみに絞っているので、レコード数が少ない |
| デメリット | 説明 |
|---|---|
| 全ページ横断での分析要望が出てきた時の修正コストが高い | ページタイプが増えるたびに、新たなファクトテーブルの作成と、 統合したファクトテーブルの修正が必要になる |
| 管理するテーブルの数が増える | ページタイプが増えるたびに、新たにファクトテーブルを作成する必要がある |
結論
ディスカッションの結果、方針1を採用するのが良いだろうという結論になりました。
理由は、ファクトテーブルの汎用性が高いためです。
方針1のファクトテーブルは、全ページ横断での分析、商品ページの分析の両方のユースケースを抑えることができます。商品ページの分析をする上で、パフォーマンスがボトルネックになる場合は、方針2のテーブルに切り出して使用するという選択肢をとることも出来ます。
また、方針1のデメリットは考慮する必要がないパターンも考えられます。例えば、アクセスの量、ページタイプの数、ページタイプに付帯する属性の数が多くないケースなどです。
最初から過度に複雑なモデリングをするのは避け、状況に応じてとれる選択肢を増やしておくというのがスマートな設計だと考えました。
ただ、ディスカッションしていく中で方針1を採用する際、解決すべき課題がいくつかあることも分かりました。
方針1を採用した場合に解決すべき課題
商品ページであれば商品IDのように、ページごとに固有の情報が存在します。
方針2の場合は、ページごとにテーブルが分かれているため、専用のカラムを設ければ済みます。 しかし、方針1を採用した場合、1つのテーブルにまとまっているため「ページタイプやページ属性」をどのように扱うかが課題となります。
アドバイザーの皆様が具体的なテーブル構成について2つの案を考えてくださいました。
①ページディメンションテーブルを作成し、そこでページタイプやページ属性を管理するパターン
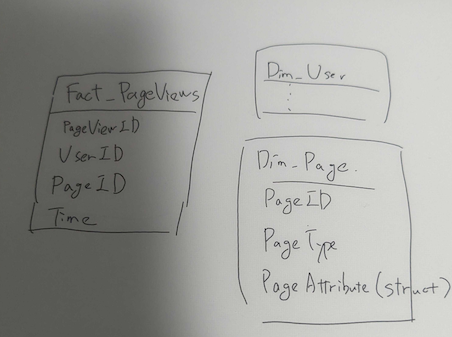
②ファクトテーブルでページタイプやページ属性を管理するパターン
| fact_access_log | |
|---|---|
| timestamp | |
| user_id | |
| page_type | 例えば “item_detail” “search” など URLから変換する? |
| event_params | page_typeによって含む key は異なる 例えば{“item_id”: 1234, “query”: “掃除機 東芝“, “content_id”: 5678} など |
上記の2つの意見は、「ページタイプやページ属性」をファクトテーブルに置くか、ディメンションテーブルに置くかという点で設計方針が異なります。
ここから、上記の2つの選択肢の内、どちらが適しているかという議論に発展しました。
これを議論ポイント1とします。
また、両者共通でページタイプ毎に違う属性値をStruct/Json型で管理していますが、他にとれる選択肢はないかについても考えました。
こちらは議論ポイント2とします。
議論ポイント1:ページタイプやページ属性をファクトテーブル、ディメンションテーブルのどちらで管理するか
方針1:ファクトテーブルで管理する
| メリット | 説明 |
|---|---|
| ファクトテーブルとして汎用性が高い | ページタイプによって絞り込みや取得するカラムの選択ができるので、 分析用途に応じて新たなファクトテーブルの切り出しができる |
| SQLでの取り扱いが簡単 | ビジネスイベント発生時の属性をファクトテーブルに紐づけることができるため、 属性の履歴値を取得するロジックをSQLで書く必要がない |
| デメリット | 説明 |
|---|---|
| ディメンションとして再利用できない | ディメンションテーブルとして切り出していないので、複数のファクトテーブルで使用できない |
方針2:ページディメンションテーブルで管理する
| メリット | 説明 |
|---|---|
| 複数のビジネスイベントの分析で使用できる | ディメンションテーブルとして切り出すことで、ビジネスイベント間で使用するテーブルを共有できる |
| デメリット | 説明 |
|---|---|
| クエリパフォーマンスが低くなる | Webサービスが大量のページを保有する場合、ディメンションテーブルが縦長になってしまう(モンスター・ディメンション) |
結論
ディスカッションの結果、方針1を採用するのが良いだろうという結論になりました。
理由は、課題1の結論と同じく汎用性が高いからです。課題1では1つのテーブルで柔軟に対応できる設計が好ましいと考えました。方針1を選ぶほうが設計ポリシーが一貫しています。
なお、ディメンショナルモデリングの一般的な手法に則った場合、「ページ」はビジネスイベントの「What」や「Where」に該当する存在なので、本来であればディメンションになるべき要素です。
ただ、今回のケースだと、ページディメンションはユーザーのアクセス分析で使用される以外の使い所が少ない(いわゆる「適合ディメンション」[Confirmed Dimension]ではない)ため、ディメンションテーブルとしての汎用性は低いだろうと考え、このような結論に至りました。
複数のビジネスイベントで使用できる場合は、方針2を選び、ディメンションテーブルとして切り出す方が良いケースも存在しそうです。
議論ポイント2:ページタイプ毎に変わる属性をどのように扱うべきか
先ほどの議論では PageAttribute や event_params といった属性を Struct/Json型で管理する想定でしたが、他の選択肢についても検討しました。
方針1:nullを許容し横長のテーブルを作成する
StructやJsonをパースして、"key: value" ごとに新しいカラムを設けます。
商品ページには商品ID、コンテンツページにはコンテンツIDなど、ページタイプによって含まれている属性が違うので、対応しない属性のカラムはnullになります。
| メリット | 説明 |
|---|---|
| データ利用者が扱いやすい | テーブル結合やデータの加工処理が必要ない |
| デメリット | 説明 |
|---|---|
| データがわかりにくくなる | 属性の数が多いとテーブルが横長になる 利用可能なタイプと属性の組み合わせが分かりにくくなる |
| nullが多く見栄えが悪い |
方針2:別テーブルに切り出す
ページタイプごとに必要な属性を別テーブルとして切り出します。
| メリット | 説明 |
|---|---|
| nullが少なく見栄えが良い | |
| 階層構造を理解しやすい | 属性が複数階層を持つ場合、別テーブルとして切り出すことで、 階層構造を理解しやすくなる |
| デメリット | 説明 |
|---|---|
| クエリパフォーマンスが低い | 結合するテーブルが増える |
| データ利用の難易度が少し高い | 結合するテーブルが増える |
| 管理するテーブル数が増える |
方針3:STRUCTやJSON型を使用する
すべて1つのカラムにまとめます。
| メリット | 説明 |
|---|---|
| 1つのカラムで階層構造を表現できる | |
| アクセスログやGA4の項目追加時に対応が不要 | データソースに半構造データが含まれる場合、データ加工の必要がない |
| デメリット | 説明 |
|---|---|
| データカタログツールでのメタデータ付与ができない | 現状、データカタログツールの多くは、カラム単位でメタデータを付与しているため、 1カラムの中に複数の意味を持つカラムを適切にラベリングできない(カラムへの権限付与が難しくなる) |
| マスキング処理などのデータ加工の難易度が高い | 特定のキーにセンシティブなデータが含まれている場合、 そのキーの値のみ加工処理をするロジックが必要になる |
| データ利用の難易度がかなり高い | 半構造化データが提供されることになるので、 SQLでの取り扱いが難しくなる |
結論
ディスカッションの結果、方針1を採用するのが良いだろうという結論になりました。
今回のケースだと、ページタイプに付帯する属性の数もそこまで多くないので、データ利用者が混乱するほど横長のテーブルになることはなさそうです。
データウェアハウスにおけるデータモデリングの目的に立ち戻ると、やはり「データを分析しやすいか」という点にこだわる必要があります。
それを踏まえると、方針3については、極力採用したくないなと思います。 特に「カラム単位でメタデータが付与できない(権限付与が難しくなる)」「マスキング処理の難易度が高い」というデメリットは、ビジネスにおいては致命的かと思います。
方針3を採用するケースがあるとすれば、例えばGA4のイベントデータなどの半構造化データを含むデータソースを前処理せずそのまま使いたいという場合で、暫定的な対応方針として採用するケースなどでしょうか。 そのような場合でもUDFを使用するなどして、なるべくユーザーがデータ構造を意識せず、データ利用できる何かしらの工夫は必要になりそうです。
方針2については採用の検討余地がありそうです。データが複数階層を持ち、属性の数がかなり増える場合や、データ利用者がSQLに慣れていてテーブルの結合が適切にできるのであれば、方針2を採用しても良いかもしれません。
まとめ
フローチャートで今回のディスカッションで出てきた課題とその対応方針について図示しました。
読者の皆様が、データモデリングを進めていく上で何かの参考になれば幸いです。
おわりに
今回の議論を経て、ユーザビリティを最優先しながらも過度なモデリングは避けるというのが、データモデリングにおいて重要なポイントであるということを再認識できました。
風音屋では、モデリングに関する議論を行うための専用チャンネルがあったり、データモデリング強化月間があったりと、データモデリングについてワイワイ話す場所や機会がたくさんあります。
データモデリングにご興味のある方は、是非カジュアル面談からでもお申し込みをご検討ください!