
GA4のデータをSQL(BigQuery)で扱うハンズオン
風音屋の共同代表 @mizuki_takenobu です。 この記事ではアクセス解析ツール「Google Analytics 4」(以下GA4)のデータをSQLで扱う方法をサンプルコードとともに紹介します。
背景
2023年7月のUniversal Analytics(以下UA)の終了にあたり、デジタルマーケティング担当の方々からGA4の相談を受けることが増えています。 UAとGA4ではデータの種類や定義が異なりますし、コンソール上で試行錯誤するには限界があります。 BigQueryで柔軟に集計するニーズが高まっています。
弊社では半年ほど前から簡易的なドキュメントをご用意し、顧問先に提供してきました。 新規のお客さまからのご相談が日々増えているため、テックブログで公開することにしました。
想定読者
- データ分析に興味のあるデジタルマーケティング担当
- デジタルマーケティング改善に興味のあるデータアナリスト
特に「GA4やBigQueryの画面を見たことがある」「SQLについては何となく分かる」「GA4のデータをSQLで触ってみたい」という方々を想定しています。
想定課題
GA4のデータをBigQueryで取り扱うにあたり、主に2つの課題を抱えていると感じました。
- 従業課金が怖くて気軽に試せない
- データの構造が分かりにくい
課題1. 従量課金が怖くて気軽に試せない
BigQueryはGA4のデータを手軽にSQLで扱うことができる反面、デフォルトだと従量課金の設定になっています。 大量のデータを集計しようとするとその分だけ請求金額が高くなってしまいます。 自社のWEBサイトのアクセスが多い場合ですと、GA4 のデータ量も多いので、無邪気にSQLを実行できません。
課題2. データの構造が分かりにくい
初心者向けのSQLの教材を見ると、正規化されたデータを題材にしているものが多いです。 しかしGA4のデータは綺麗なテーブル形式にはなっていません。 カラム(列)も多いので、初心者にはハードルが高く感じられるでしょう。
"従量課金"への解決策:公式サンプルデータを使う
「従業課金が怖くて気軽に試せない」という課題については、公式サンプルデータの利用をオススメしています。
BigQueryにはGA4のサンプルデータが公式で提供されていることをご存知でしたか?
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_[YYYYMMDD] というテーブルに3ヶ月分のECサイトのダミーデータが含まれています。
データ量が少ないので、安心してSQLを試すことができます。
このデータの詳細は公式ドキュメント「Googleアナリティクス4 eコマースウェブ実装向けのBigQueryサンプルデータセット」で説明され、以下のようなサンプルSQLが紹介されています。
SELECT
COUNT(*) AS event_count,
COUNT(DISTINCT user_pseudo_id) AS user_count,
COUNT(DISTINCT event_date) AS day_count
FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
"データ構造"への解決策:4ステップでSQLを試す
「データの構造が分かりにくい」という課題については、4つのステップで進むと理解が進みます。
STEP1. 特徴を把握する
GA4のデータには以下3点の特徴があり、一般的なテーブル構造よりも複雑に見えます。
- イベントごとに行が作られている。例えば、初回訪問の1つ目のPV(ページビュー)では
"first_visit","session_start","page_view"という3つのイベントが1行ずつ作られる。 - 1行のイベントに複数のパラメーターのkeyが含まれる。例えば、
"page_view"イベントには"page_referrer"も"page_location"も含まれている。 - パラメーターのvalueを扱うためのカラムが複数ある。例えば、
"page_referrer"パラメータの値はstring_valueカラムに入るが、"ga_session_id"パラメータの値はint_valueカラムに入る。残念なことに同じパラメーターでも別のカラムに振り分けられることがある。例えば、通常は"abc","de1","23f"といった文字でstring_valueカラムに振り分けられるとしても、たまたま"456"という値が入ると「これは数値だ」と解釈されてint_valueカラムに振り分けられてしまう。
これらのことを理解した上でSQLで実際に試してみましょう。
STEP2. お手本のSQLを試す
以下のSQLでは、ページURLに特定の文字列「Apparel」(アパレル)が含まれるページビューを絞り込んで、日付別にUUを集計しています。
SELECT
-- 日付別
DATE(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo') AS day,
-- UUを集計
COUNT(DISTINCT event.user_pseudo_id) AS uu,
FROM
-- サンプルデータからデータを抽出
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` AS event
LEFT JOIN
-- CROSS JOIN ではなく LEFT JOINを使う。Appendixで後述します。
UNNEST(event.event_params) AS event_params
WHERE TRUE
-- 1. 節約のために対象期間を絞る
AND event._TABLE_SUFFIX BETWEEN '20210125' AND '20210131'
-- 2. イベントを絞りこむ
AND event.event_name = 'page_view'
-- 3. 抽出条件を明記する
AND (
event_params.key = 'page_location'
AND event_params.value.string_value LIKE "%Apparel%"
)
GROUP BY day
ORDER BY day DESC
このサンプルSQLを参考にして、WHERE句の「対象期間」「イベント」「抽出条件」や、SELECT句の「集計指標」を変更すれば、簡単に必要なデータを取得できます。
STEP3. 公式ドキュメントを読む
データの詳しい定義は公式ドキュメント「[GA4] BigQuery Export スキーマ」に記載されています。
例えば「user_id」カラムと「user_pseudo_id」カラムの違いについて、以下のように説明されています。
user_id:setUserId APIによって設定されるユーザーID。user_pseudo_id:ユーザーの仮のID(アプリインスタンスIDなど)。
「setUserId API」はドキュメント「ユーザーIDを設定する - Firebase」で説明されています。
アプリケーションごとに固有のIDを発行してFirebase/GA4に送るときにこのカラムを使います。
つまり、
- ログインIDなど各社で定義され、アプリケーションでGAに送っている値を使うときは「
user_id」カラム - GA側が自動で各デバイスに付与する値を使うときは「
user_pseudo_id」カラム だとわかります。
SQLを書いていて疑問に思うことがあったらぜひ公式ドキュメントを読みましょう。
STEP4. 他のサンプルSQLを試す
他にも公式ドキュメント「[GA4] BigQuery のデータからオーディエンスを抽出するクエリのサンプル」では以下のようなサンプルSQLが紹介されています。
- N日間アクティブユーザー:過去N日間にイベントが1件以上記録されているユーザー
- N日間非アクティブユーザー:過去M日間のユーザーのうち、過去N日間にイベントが1つも記録されていないユーザー (M > N)
- 頻繁にアクティブなユーザー:イベントが1回以上記録された日が過去M日間にN日以上あったユーザー
- 高度にアクティブなユーザー:過去M日間にN分以上アクティブだったユーザー
- フィルタ付きコホート:前の週にGoogleキャンペーンを通して獲得したユーザーのオーディエンス
自分が試したいテーマに近いものがあればぜひ参考にしてください。 STEP1〜STEP4を経ることでGA4のデータに習熟できるはずです。
Appendix
Appendix1. SQLのUNNEST()について
複雑なデータ構造をシンプルなテーブル構造に変換できるのが UNNEST() という関数です。
SQLを使い始めたばかりの方にとっては馴染みがないかと思います。
詳しい案内は「配列内の要素をテーブル内の行に変換する - BigQuery」というページを参照してください。
UNNEST() は CROSS JOIN ではなく LEFT JOIN で結合しましょう。
以下のブログ記事が参考になります。
INNER JOINやCROSS JOINではなくLEFT JOINを使うことに注意してほしい。 ネット上でBigQueryのUNNESTのサンプルクエリを探すと、暗黙的にCROSS JOINを用いている例が散見される。 しかし、INNER JOINやCROSS JOINだと該当カラムがNULLだった場合にレコードが欠損してしまう。
Appendix2. BigQuery Utilsについて
GoogleCloudPlatform/bigquery-utilsというUDFを使うとSQLがさらにシンプルになります。 以下のクエリを実行すると先程のサンプルクエリと同じ結果を得ることができます。
SELECT
DATE(TIMESTAMP_MICROS(event.event_timestamp), 'Asia/Tokyo') AS day,
COUNT(DISTINCT event.user_pseudo_id) AS uu,
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` AS event
-- LFET JOIN と UNNEST が不要になる
WHERE TRUE
AND event._TABLE_SUFFIX BETWEEN '20210125' AND '20210131'
AND event.event_name = 'page_view'
-- パラメータ指定が1行で済む
AND bqutil.fn.get_value("page_location", event.event_params).string_value LIKE "%Apparel%"
GROUP BY day
ORDER BY day DESC
Appendix3. さらなるデータ分析の可能性
GA4はBigQueryを活用したり他の広告データなどと組み合わせることで柔軟なデータ分析が可能となります。 例えば「新しく出稿したオンライン広告が自然流入からシェアを奪っている」「CPAは好調だがROASは悪化している」といったことを即座に検知できます。
さらなるデータ分析を効率よく実現するには、データモデリングの設計が必要になります。 SQLを組み合わせて複数の中間テーブルを作ることで、さまざまなデータ抽出を効率化できます、 専門性の高い内容なのでデータエンジニアに相談することをお勧めします。
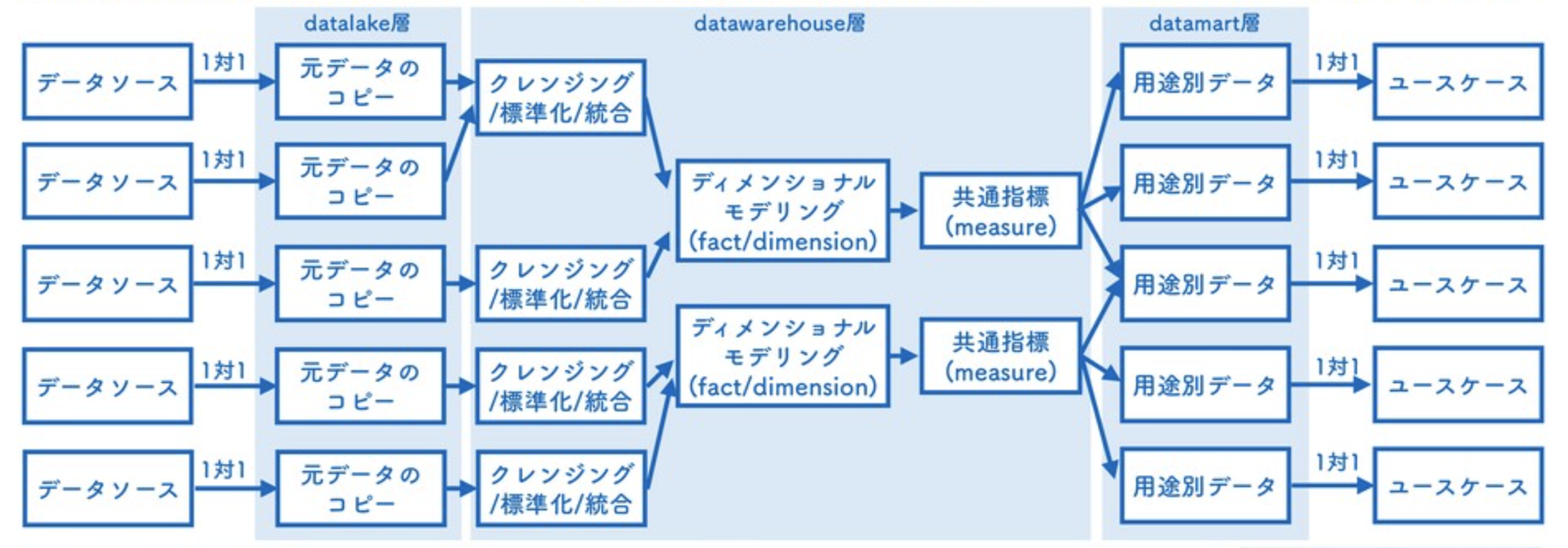
風音屋ではデータモデリングの書籍を出版予定ですので、よかったら参考にしてみてください。 書籍の発売時にはTwitter @kazaneya_PR で告知します。 ぜひフォローよろしくお願いします。
最後に
風音屋では、GA4、BigQuery、Google DataStudio(日本語名:Googleデータポータル)によるモニタリング環境の構築・運用を支援しています。 クライアントのデータ経営を支えるために一緒に働く仲間を募集していますので、採用ページよりお気軽にお声がけください。 データ分析に興味のあるマーケティング担当や、マーケティング改善に興味のあるデータアナリストの方は、ご自身の専門性を伸ばしながら幅広い案件で活躍できます。