
外部組織に分析目的でデータを提供するインフラ設計において考慮すること
datatech-jp Advent Calendar 2023 の25日目の記事です。
本記事では、外部組織にデータ分析を委託するためのインフラ設計について、いくつかの論点を紹介します。
この内容は、Google Cloud Next Tokyo’23 におけるゆずたそさんの発表「データ分析の授業における Google Cloud の活用事例」を聞いた後に行ったディスカッションがベースになっています。
対象読者
- 外部組織にデータ提供を行っている、あるいは検討しているエンジニア
- 外部提供されたデータの分析を行っている、あるいは検討しているアナリストや研究者
前提:Next Tokyo'23 の発表内容について
「データ分析の授業における Google Cloud の活用事例」という発表では、企業のマスキング済みデータを大学の授業のために提供した事例が紹介されました。具体的には、以下のようなデータ提供インフラを構築しました。
- 企業は、自社データを自社の Google Cloud プロジェクトにある Analytics Hub 経由で学生に提供
- 学生は、外部企業のデータを授業用の Google Cloud プロジェクトにある Analytics Hub 経由で取得し、同じプロジェクトにある BigQuery と Vertex AI Workbench で分析
- 分析のログは Cloud Logging に記録され、監査レポートの形式で企業に報告される
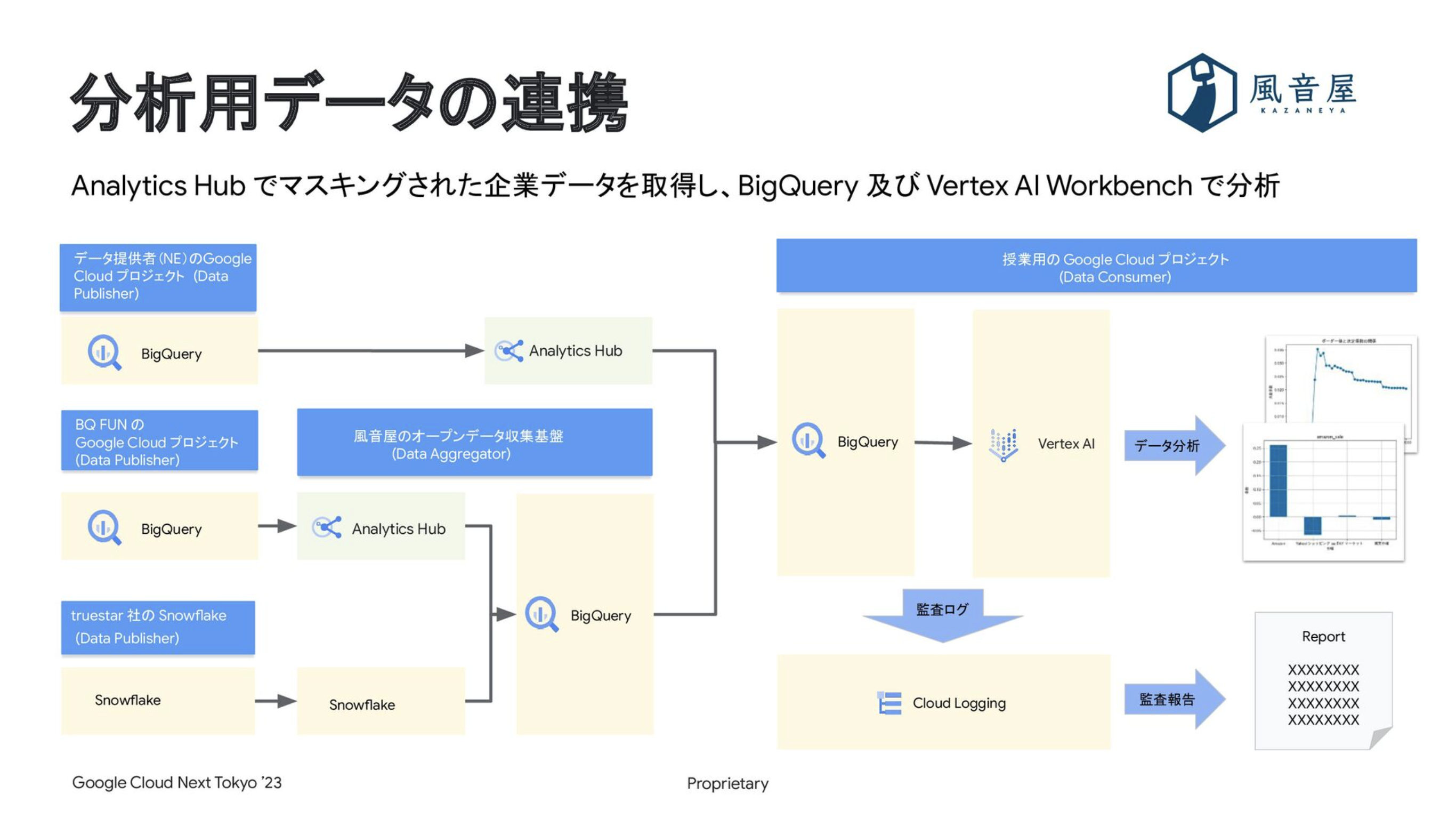
発表の詳細は、スライド資料をご覧ください。
前提:分析目的のデータ提供インフラ設計に求められるもの
大学などの外部組織にデータ分析を委託するため、社内のデータを提供するインフラを設計するには、「データの安全性」と「分析の自由度」を両立させる必要があります。
外部組織にデータを提供する上では、「データの安全性」を担保することが大前提です。具体的な観点としては、分析者の同意を得ていない個人情報が提供データに含まれていないか、外部組織がデータの利用用途をきちんと守っているか、情報漏洩が起きていないか、といった点が挙げられます。
このようなリスクを許容範囲に抑えることは必須ですが、一方で、データの安全性をあまりにも重要視しすぎると「分析の自由度」が下がってしまいます。例えば、データの匿名性を高めるために集計済みのデータを共有すると、個人単位の分析はできません。情報漏洩リスクを不安視し過ぎると、何もデータを渡せなくなってしまいます(何も渡さないのが一番低リスクだから)。 そのため、まずは分析に必要な最小限のデータを提供し、分析結果を受け取り、それを踏まえてより多くのデータを提供していく、といった形で、分析の自由度を段階的に高めていくのがよいでしょう。
これらの観点を踏まえて、実際に行なった議論をいくつか紹介します。
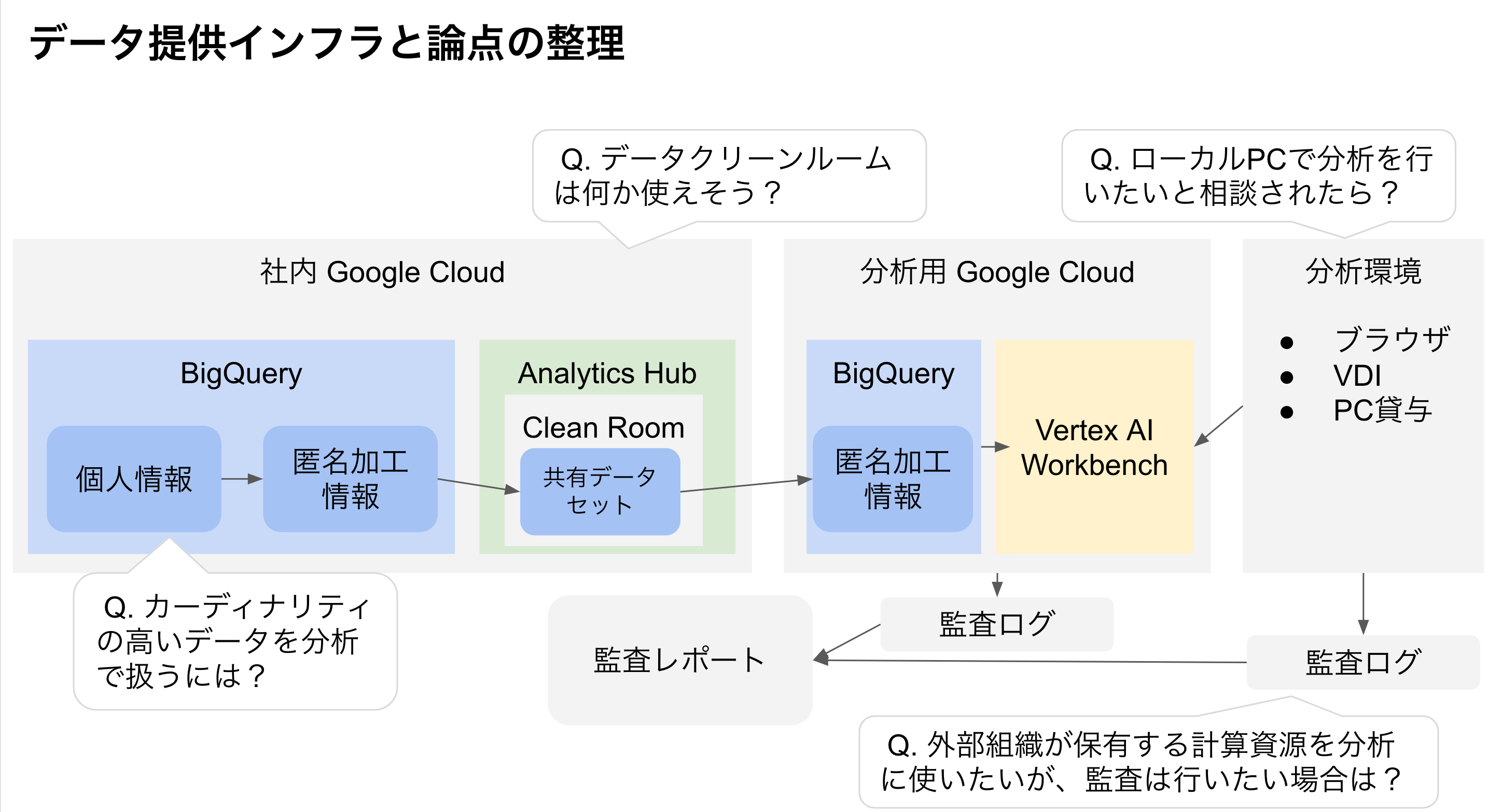
Q. カーディナリティの高いデータを分析で扱うには?
A. k匿名性を担保した属性情報を用意して代わりに使う。LLMに属性情報を生成させるのも手段の一つ
k匿名性とは、データの匿名性の指標で、「同じ属性のレコードが少なくともk個以上あること」という状態を表します。
例えば、社員名やプロフィールといったカーディナリティの高いデータは多くの情報を含んでいるため、分析を行う上でとても有用です。ただし、これらのデータはそのまま Google 検索にかけるだけで、実在する特定の個人と結び付いてしまうことがあります。これでは、データのk匿名性が担保されていません。何かしらの形で粒度を粗くして、全く同じ値を持つデータが少なくともk個以上存在するようにしたいです。
社員属性のデータがすでに存在すれば、社員名の代わりに使用できます。ただし、社員名やプロフィールの情報を十分に活用できていませんし、分析で使いたい分類と既存の社員属性が必ずしも一致するとは限りません。また、ルールベースで社員属性を抽出するやり方もありますが、文章から個々の属性を上手く抽出するルールを作るのには手間がかかります。そのような場合は、LLMを用いて、分析の目的に沿った社員属性を社員名やプロフィールから生成することができます。具体的な手順は以下です。
- 社員名やプロフィールのサンプルデータをいくつか用意
- 分析の要件に合わせた属性を生成できるようにプロンプトを調整。「以下の社員属性の中から当てはまるものを選んでください」という選択形式にする
- 完成したプロンプトを用いて、すべての社員について社員属性を生成
- k匿名性が守られているかチェック
- 社員属性のみを外部組織に提供
LLMを用いることで、欲しい属性の方向性をプロンプトで調整できるようになります。分析の要件に合わせた属性を手間をかけずに生成できますし、社員に関する他の文章(所属部署の情報や、評価の情報など)を活用することもできます。
ただし、以下の2点には注意してください。
- 一般的に、LLMによる文章生成は時間がかかります
- LLMの中には入力データを学習に使うものもあります。個人情報をLLMに入力する場合は、事前に規約を確認してください
Q. LLMが生成した属性情報の精度はどれくらい高い?
A. 技術検証では8-9割の精度。目視で確認した限りでは、違和感のある属性が少ないと感じた
トイデータで技術検証を行い、生成された属性を目視で確認したところ、8-9割の精度でした。そのため、(専門的な分類はさておき)少なくとも汎用的な分類であれば、ある程度の精度を期待できるのでは、という議論を行いました。また、将来マルチモーダルなLLMが普及すれば、画像など文字以外のデータ形式からでも属性生成ができるようになるだろう、といった未来の話をしました。
Q. 「データクリーンルーム」は何か使えそう?
A. 「プライバシーポリシー」機能を使う前提であれば「限定公開データエクスチェンジ」を代替しうる
2023年8月末に、Analytics Hub に新しく「データクリーンルーム」という機能が登場しました。この機能は、機密および保護されたデータ共有のユースケースに対処するのに役立ちます。
今回は、以下の2点について説明します。
- クリーンルームと組み合わせて使う「プライバシーポリシー」機能とは
- 「データクリーンルーム」と「限定公開データエクスチェンジ」の違い
「プライバシーポリシー」機能とは
Analytics Hub を用いてk匿名性を担保した状態でデータを外部組織に提供するには、BigQueryの「プライバシーポリシー」機能を組み合わせて使います。これは、BigQuery のビューやクエリに対し、集計後のデータにおけるk匿名性の担保を強制するものです。今回はビューへの適用に絞って話します。
データ提供者はあらかじめ、ビューにプライバシーポリシー(プライバシーユニット列と閾値)を指定します。すると、ポリシーが指定されたビューは GROUP BY を使って集計することが強制されます。プライバシーユニット列に対してログ数が閾値未満になる行は、集計結果から自動的に削除されます。
例えば、生徒ごとのテストの点数が記録された「テストの成績」テーブルに対して、プライバシーユニット「生徒番号」列と閾値「3」を指定するとします。テストの結果を点数ごとに GROUP BY して生徒数を集計するクエリを発行すると、紐づく生徒数が多い点数は生徒数が分かりますが、紐づく生徒数が3人未満の点数はすべて集計結果から除外されるので、それらの点を取った生徒数は分かりません。
「データエクスチェンジ」との比較
Analytics Hub には、データを外部組織とやり取りするための「データエクスチェンジ」という機能が以前から存在します。この機能には「一般公開データエクスチェンジ」と「限定公開データエクスチェンジ」の2種類があります。外部組織に分析目的のデータ提供を行う場合、この「限定公開データエクスチェンジ」が選択肢の一つです。
新登場の「データクリーンルーム」と既存の「限定公開データエクスチェンジ」の間に、基本的な機能の差はありません。k匿名性を担保する「プライバシーポリシー」機能は、クリーンルームとエクスチェンジどちらとも組み合わせて使うことができます。
一方で、クリーンルームは機密および保護されたデータ共有のユースケースに最適化されており、使い勝手が異なる点がいくつかあります。
- 共有データセットの個々のテーブルにポリシーを設定しているかどうかを、画面上で確認できる
- ポリシーが設定されていないテーブルをクリーンルームに追加しようとすると警告が出る
- 共有データのコピーやエクスポートを有効にできない仕様になっている
- ただし、クエリ結果のコピーとエクスポートは可能
「プライバシーポリシー」機能を用いて機密情報を外部組織へ安全に提供したい場合は、データクリーンルームを使うのも一つの選択肢になるでしょう。
Q. ローカルPCで分析を行いたいと相談されたら?
A. データの持ち出しリスクをどこまで重く見るかに応じて、適切な分析環境を提供する
分析者は、Google Cloud を通じて受け取ったデータを自身のローカルPCに保存し、使い慣れたツールを用いてデータ分析を行いたいと要望を出すことがあります。しかしデータ提供者は、分析者のローカルPCに保存されたデータがきちんと管理されているか、分析完了後にきちんと削除されたのかを確認できません。そのため、ローカルPCへのデータの保存を許可すると、情報漏洩リスクが高まる懸念があります。データの持ち出しを防ぎたい場合は、代わりに以下のような分析環境を提供することができます。
| 選択肢 | 提供単位 | 概要 | メリット | デメリット |
|---|---|---|---|---|
| Google アカウント | ブラウザ | 専用の Google アカウントを外部組織の分析者に発行する方法 Google Cloud の IAMを用いて権限を管理 分析者はブラウザ上で分析を行う データをブラウザの外に持ち出すことを禁止 |
特別な分析環境を用意する必要がないのでコストを抑えられる アカウントを削除すれば分析者の手元にデータが残らない |
データをブラウザの外に持ち出せないので、ブラウザの外で動作する分析ツールを使うことができない 分析ツールが BigQuery や Vertex AI Workbench などに限られてしまう |
| VDI | OS | VDI(仮想デスクトップ)を外部組織の分析者に提供する方法 分析者はローカルPCからVDIにアクセス データをVDIの外に持ち出すことを禁止 |
物理的なPCを用意するほどのコストがかからない 好きな分析ツールを使用できる VDIを削除すれば分析者の手元にデータが残らない |
VDIを用意するコストがかかる PC貸与ほどの分析の柔軟性はない |
| PC貸与 | ハードウェア | 物理的なPCを外部組織の分析者に提供する方法 分析者はそのPCを用いて分析を行う データを、貸与したPCから持ち出すことを禁止 |
好きな分析ツールを使用できる VDIより柔軟性がある PCを返送してもらえば分析者の手元にデータが残らない |
PCを用意するコストがかかる PCの発送や返送に手間がかかる |
これらの選択肢は相反するものではなく、むしろ以下の図のような階層になっています。
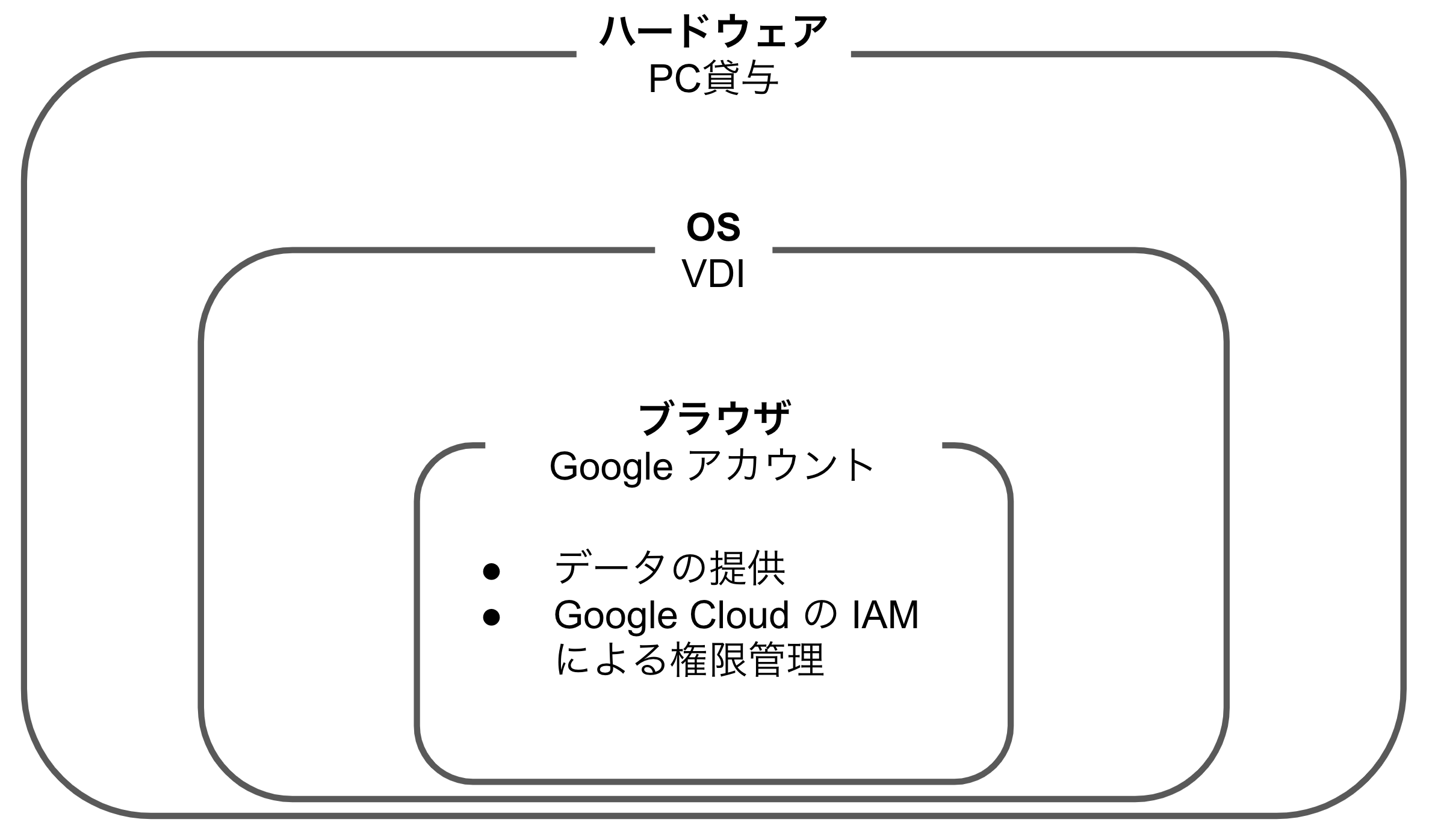
また、「データの提供はIAMで管理し、分析環境はVDIを提供する」といった形式で、これらの選択肢を組み合わせることもできます。
Q. 外部組織が保有する計算資源を分析に使いたいが、監査は行いたい場合は?
A. そのマシンの監査ログを提出してもらう選択肢もある
Google Workspace や Google Cloud で分析を行う場合は、ログイベントや Cloud Logging の監査ログからレポートを作成することが出来ます。一方で、外部組織が独自のGPUリソースを持っているケースなど、データを外部組織のインフラに持ち出してから分析を行いたい場合もあります。持ち出しは許可するが監査は行いたい場合は、分析に使用するマシンの監査ログを提出してもらうことで、データが想定外の使われ方をしていないかチェックすることもできます。
ただし、追加の監査工数がかかるので、相手との信頼関係や契約書の内容、渡すデータのリスクなどを踏まえてバランスを取るのがよいと考えています。
まとめ
本記事では、外部組織にデータ分析を委託するためのインフラ設計について、論点や解決策をいくつか紹介しました。
組織を跨いだデータ共有は、Analytics Hub をはじめとするモダンなサービスがここ数年で出始めたばかりです。個人情報保護法など分析者のプライバシーを保護する法律を遵守しながら、より自由な分析を行えるようにするための仕組みは、企業がデータの利活用に注力するようになる中で、今後ますます発達するのではないかと考えています。