
dbt CoreとGitHub Actionsで構築するCI環境の実践Tips
dbt Core と GitHub Actions で CI を構築する際、「毎回すべてのモデルをテストしていて時間がかかる」「PRごとに独立したテスト環境をどう用意すればいいか分からない」といった課題に直面していませんか?
dbt Cloud を利用すれば Slim CI などの便利な機能が標準で提供されていますが、dbt Core で同様の体験を実現するには、CI スキーマや manifest.json の管理など、一手間加えた実装が必要です。
この記事では、dbt Cloud を利用せず、dbt Core で CI を構築する際に役立つ実践的な Tips をご紹介します。
dbt Cloud と dbt Core の CI は何が違うのか
はじめに、dbt Cloud と dbt Core における CI の違いを簡単に整理します。 dbt Core でなぜ自前の実装が必要になるのか、その背景を理解することが重要です。
- dbt Cloud
- Slim CI を備えた CI 機能が標準で提供されており、GUI 上で比較的簡単に設定できます。
manifest.jsonの管理といった、Slim CI の実現に必要な状態管理も dbt Cloud が自動で行ってくれます。
- dbt Core
- GitHub Actions や GitLab CI といった外部の CI/CD サービスと連携し、パイプラインを自前で構築する必要があります。
- Slim CI を実現するためには、
manifest.jsonの比較と状態管理を自分たちで設計し、実装する必要があります。 - CI 実行時に利用する一時的なスキーマの管理やクリーンアップも、自前で実装する必要があります。
このように、dbt Core で CI を実現するには一手間かかりますが、その分柔軟性が高く、特定の要件に合わせた細かいカスタマイズが可能です。 この記事では、後者の dbt Core で CI を組む際の具体的なTipsを解説していきます。
dbtにおける CI の基本コンセプト
具体的な実装の Tips に入る前に、dbt における CI の基本的な考え方である「CI スキーマ」と「Slim CI」についておさらいします。
CI スキーマ: PRごとの独立したテスト環境
CI を構成する上で重要なのは、開発中の変更が本番データに影響を与えないようにすることです。 そのために、CI 専用のデータベーススキーマ(CI スキーマ)を用意し、その中でモデルのビルドとテストを実行します。
複数のプルリクエスト(PR)が同時に進行することを考慮し、CI スキーマは PR ごとに一意になるように作成するのが一般的です。 このとき、 PR 番号をスキーマ名に含めることで、各 PR が互いに影響を与えない独立した環境を確保できます。
今回は、PR 番号が 123 のとき、 _ci_pr_123 の形式の prefix をスキーマ名に付与することとします。
たとえば、 mart スキーマに対応する CI スキーマは _ci_pr_123_mart となります。
なお、スキーマ名の先頭にアンダースコアを付けているのは、スキーマ一覧の末尾に表示させるための工夫です。
Slim CI: 賢くテストして時間とコストを節約
プロジェクトが大きくなるにつれて、すべてのモデルを毎回ビルドしてテストすると、CI の実行に時間がかかり、コンピューティングリソースのコストも無視できなくなります1。 そこで登場するのが「Slim CI」という考え方です。
Slim CI は、PR で変更があったモデルと、その下流にある依存モデルのみを対象にビルドとテストを行う手法です。 これにより、CI の実行時間とコストを大幅に削減できます。
dbt Core で Slim CI を実現するには、主に以下の2つのオプションを利用します。
--select state:modified+: 変更があったモデル(state:modified)とその下流(+)を選択します。--defer: 変更がない上流モデルを参照する際に、CI スキーマではなく「変更の基準となる状態」の環境のオブジェクトを参照させます。
これらのオプションを機能させるためには、「変更の基準となる状態」(通常は main ブランチの最新の状態)が記録された manifest.json ファイルが不可欠です。
CI スキーマと Slim CI の組み合わせ
CI スキーマと Slim CI を組み合わせることにより、「変更の基準となる状態」と「変更後の状態」を比較し、必要なモデルだけを CI スキーマに作成する、といったことが実現できます。
たとえば、本番環境において以下のようなスキーマ構成、処理の流れになっているとします。
rawスキーマにソースデータが入っているrawスキーマのソースを参照してwarehouseスキーマのモデルが作られるwarehouseスキーマのモデルを参照してmartスキーマのモデルが作られる
ここで、warehouse スキーマのモデルを更新する PR (#123) が作成されたときの CI の処理は以下のようになります。
rawスキーマのソースを参照して_ci_pr_123_warehouseスキーマのモデルが作られる_ci_pr_123_warehouseスキーマのモデルを参照して_ci_pr_123_martスキーマのモデルが作られる
まず、ソースは dbt で作成するものではないので、常に「変更の基準となる状態」の環境のデータを参照します。
よって、ここでは本番スキーマである raw スキーマを参照します。
次に、warehouse スキーマのモデルが更新されたので、これに相当する CI スキーマ(_ci_pr_123_warehouse)にモデルを作成します。
最後に、warehouse スキーマのモデルに依存している mart スキーマのモデルについても、これに相当する CI スキーマ(_ci_pr_123_mart)にモデルを作成します。
一方で、mart スキーマのモデルを更新する PR (#456) が作成されたときの CI の処理は以下のようになります。
warehouseスキーマのモデルを参照して_ci_pr_456_martスキーマのモデルが作られる
mart スキーマのモデルが更新されたので、これに相当する CI スキーマ(_ci_pr_456_mart)にモデルを作成します。
ところが、このモデルが依存している warehouse スキーマのモデルは更新されていないので、CI スキーマ(_ci_pr_456_warehouse)にモデルは存在しません。
そこで、代わりに「変更の基準となる状態」の環境の warehouse スキーマのモデルを直接参照します。
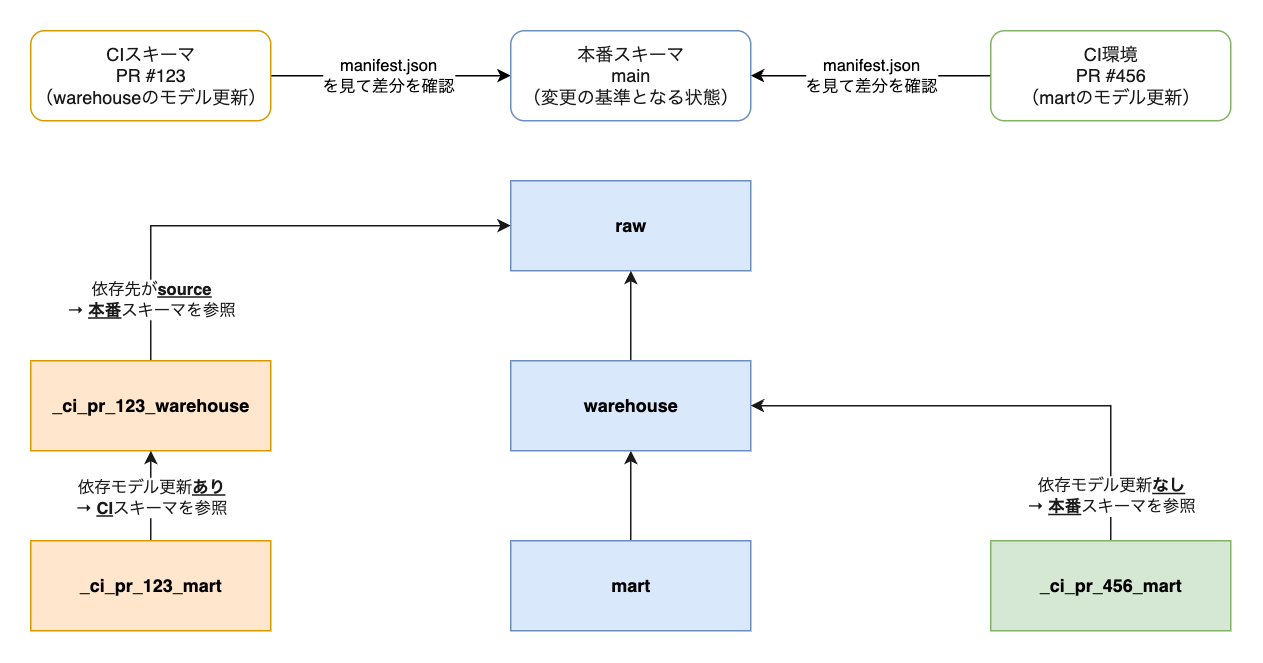
このように、CI スキーマと Slim CI を組み合わせると、CI ごとに必要となる最低限のモデルだけを CI ごとに分離したスキーマに作成できます。
dbt Core と GitHub Actions による CI 実装 Tips 集
それでは、dbt Core と GitHub Actions で CI を実装する際の具体的な Tips を紹介します。
1. CI スキーマの事前作成と権限設定
dbt は通常、モデルのビルド時にスキーマを自動で作成してくれますが、事前にスキーマを作成しておかないとエラーが出る場合があります。
- デフォルトスキーマにオブジェクトが作成されない場合:
generate_schema_nameマクロをカスタマイズしている場合など、特定のスキーマ配下にオブジェクトが何も作られないケースでは、スキーマ自体が作成されずに後続の処理でエラーになることがあります。特に、デフォルトスキーマが作成されない場合、dbt 実行時にエラーが発生するケースがあります。 - Slim CI でユニットテストを実行する場合: 上流のモデルが CI でビルド対象外でスキーマ自体が作成されない場合、ユニットテストでそのモデルを参照していると、入力をすべてモックしていてもエラーが発生するケースがあります。
このようなケースに対応するため、CI のワークフローの早い段階で、その PR で利用される可能性のあるスキーマをすべて洗い出して作成しておくのが安全です。以下のマクロは、dbt プロジェクト内のモデルなどが使用するスキーマをすべて抽出し、それらを事前に作成するのに役立ちます。
{% macro pr_schema_setup(database_name=target.database) %}
{% if execute and target.name == "ci" %}
{% set schema_names = graph.nodes.values()
| selectattr("resource_type", "in", ["model", "seed", "snapshot"])
| map(attribute="schema")
| unique
| list %}
{% for schema_name in schema_names %}
{% if schema_name %}
{{ log("Ensuring schema exists: " ~ schema_name, info=True) }}
{% do adapter.drop_schema(api.Relation.create(database=database_name, schema=schema_name)) %}
{% do adapter.create_schema(api.Relation.create(database=database_name, schema=schema_name)) %}
{% endif %}
{% endfor %}
{% endif %}
{% endmacro %}
また、CI を運用するためには、サービスアカウント(CI を実行するマシンユーザー)と開発者アカウントの両方に、クエリ実行に必要な権限2 とは別に、以下のような権限を適切に付与する必要があります。
- サービスアカウント: ソーステーブルの参照権限、スキーマの作成・削除権限、およびスキーマ配下のテーブルの作成・更新権限3
- 開発者アカウント: CI によって作成されたスキーマおよびテーブルの参照権限
サービスアカウントに適切な権限を付与することで CI スキーマに向けた dbt の実行が可能になります。 また、開発者アカウントに適切な権限を付与することで、CI によって作成されたデータを開発者が確認できるようになります。
ちなみに、本筋とは少しズレますが、GitHub Actions から AWS や Google Cloud などに接続する際は、認証情報をファイルとして発行・利用するのはキー流出などのセキュリティ上のリスクがあります。 代わりに、OpenID Connect(Google Cloud の場合は Workload Identity)を利用することをおすすめします。
- AWS: OIDC federation
- Google Cloud: Workload Identity Federation
2. CI スキーマ名の動的な指定
PR ごとにユニークなスキーマ名(例: _ci_pr_123)を利用するためには、dbt 実行時にスキーマ名を動的に渡す仕組みが必要です。
これは profiles.yml で環境変数を参照するように設定することで実現できます。
# profiles.yml の設定例
dbt_project:
target: dev
outputs:
dev:
# (省略)
ci:
# (省略)
schema: "{{ env_var('DBT_CI_PREFIX') }}"
CI の実行時には、PR番号を含んだ prefix を環境変数に設定した上で dbt コマンドを実行する必要があります。
たとえば、GitHub Actions のワークフローを pull_request イベントをトリガーにして起動する場合は、${{ github.event.number }} で PR 番号を取得できるので、これを加工して prefix を作成できます。
3. manifest.json の管理
Slim CI の要である manifest.json は、CI 実行間で状態を共有するために、S3 や GCS といったオブジェクトストレージに保存しておくのが一般的です。
- 保存のタイミング: 「基準となる状態」の環境へのデプロイが完了したタイミングで、その時点のプロジェクト状態を表す
manifest.jsonを生成し、所定の場所にアップロードします。 - 生成コマンド:
manifest.jsonは、dbt runやdbt compileなどのコマンド実行時に生成されます。デプロイ時にdbt runを実行しているのであれば、そこで生成されるmanifest.jsonをアップロードしましょう。デプロイ時にdbt runを実行する必要がないケースでは、代わりにdbt compileを実行し、生成されたmanifest.jsonをアップロードするフローを組み込みましょう。
CI 実行時には、この保存された manifest.json をワークフローの実行環境にダウンロードします。
このとき、ファイルの競合を避けるため、ダウンロード先のパスは dbt 実行時に manifest.json が生成されるパス(target/)以外にしておく方が無難です。
そして dbt コマンド実行時に --state オプションでその manifest.json が存在するパスを指定し、--defer オプションを付与します。
これにより、dbt は変更点を比較しつつ、CI でビルドしない上流のモデルについては、「変更の基準となる状態」の環境(--state で指定した環境)のものを参照できるようになります。
4. CI 実行環境の分離
CI スキーマを用意することでデータの分離は実現できますが、dbt の実行環境自体も分離することが重要です。 もし共有の実行環境を使っていると、他の PR でテスト中のモデルが一緒に実行されてしまうなど、意図しない挙動を引き起こす可能性があります。
たとえば、dbt の実行を ECS Task で行っている場合、CI ワークフロー内で以下のステップを踏むことで実行環境を PR ごとに分離できます。
- PR のブランチのソースコードで dbt の Docker イメージをビルドする。
- ビルドしたイメージを PR 番号などを含む一意なタグ(例:
pr-123)で ECR にプッシュする。 - そのイメージタグを指定した新しいタスク定義を作成する。
- 作成したタスク定義で
dbtコマンドを実行する。
これにより、各 PR は他の環境から隔離された状態で安全にテストを実行できます。
5. CI スキーマのクリーンアップ
PR がマージまたはクローズされた後、CI スキーマは不要になります。放置するとコストの無駄遣いになるだけでなく、データベースが乱雑になります。 そのため、不要になった CI スキーマをクリーンアップする仕組みを用意することが重要です。
シンプルなアプローチとしては、スキーマを削除するマクロを実装し、このマクロを GitHub Actions のワークフローで実行する4 方法が考えられます。
実装については、以下の記事が詳しいのでぜひ参考にしてください。
- Customizing CI/CD with custom pipelines | dbt Developer Hub
- dbt Cloudが自動で作成したBigQueryのデータセットのうち、古いデータセットを削除するマクロを運用する - yasuhisa's blog
このクリーンアップ用のワークフローを実行するトリガーとしては、以下の 2 つが考えられます。
トリガー1: スケジュールをトリガーに定期実行する
GitHub Actions の schedule トリガーなどを利用して、クリーンアップ用のワークフローを定期的に(たとえば、毎日深夜に)実行する方法です。
このアプローチでは、CI 用の prefix(今回の場合は _ci_pr_)を持つスキーマを INFORMATION_SCHEMA などから一覧で取得し、最終更新から一定期間経過したもの(たとえば、30 日以上前のもの)をまとめて削除する、といったロジックを実装します。
この方法のメリットは、何らかの理由で削除に失敗した場合でも、次の実行時にも削除してくれる点です。
一方で、アクティブな PR のスキーマを誤って削除してしまうことを防ぐために、基準となる期間をある程度長めに設定する必要があることから、本来であれば削除してよいデータがしばらくそのまま残ってしまう点はデメリットです。
トリガー2: PR のクローズをトリガーに実行する
PR がクローズ(マージも含む)されたタイミングで、関連する CI スキーマを削除する方法です。
GitHub Actions では、pull_request イベントの types: [closed] を利用して、PR クローズ時に絞ってワークフローを起動できます。
この方法の利点は、ワークフロー内で PR 番号を取得できるため、削除対象のprefix(例: _ci_pr_123)を正確に特定して削除できる点です。
これにより、「レビューが長引いているが実はアクティブな PR」のスキーマなどを誤って削除してしまう心配がありません。
また、クローズ時点で削除できるので、不要なデータが長く残ってしまうこともありません。
一方で、不要になったがクローズされず放置されている PR があると、その CI スキーマも削除されずずっと残ってしまう点がデメリットです。
どちらのアプローチを選ぶべきか?
どちらのアプローチにもメリットとデメリットがあります。
| スケジュール トリガー | PR クローズ トリガー | |
|---|---|---|
| 実行タイミング | 定期的(例: 毎日深夜) | PR クローズ直後 |
| 削除対象 | 最終更新から一定期間(例: 30 日)経過したすべての CI スキーマ | クローズされた PR に関連する CI スキーマ |
| メリット | 処理の失敗を次の実行でリカバリーできる | 削除が即時 アクティブなPRのスキーマを誤削除するリスクがない |
| デメリット | レビューが長引いている PR のスキーマを誤削除する可能性がある 削除までにタイムラグがある |
ワークフローの失敗などで削除漏れが発生する可能性がある 放置された PR のスキーマが削除されない |
どちらを選択するかは、プロジェクトの特性やチームの好みによります。
また、PR クローズ時の処理が何らかの理由で失敗した場合の備えとして、両者を組み合わせるハイブリッドなアプローチも有効です。 プロジェクトの運用スタイルに合わせて最適な方法を選択してください。
まとめ
本記事では、dbt Core と GitHub Actions を用いて CI を構築する際のTipsを紹介しました。
CI スキーマの管理、Slim CI の実現、実行環境の分離など、dbt Core で CI を運用するにはいくつかの工夫が必要ですが、一度仕組みを構築すれば、データ品質と開発者体験を大きく向上できます。
この記事で紹介した Tips が、皆さまが快適に dbt と付き合っていくための一助となれば幸いです。
参考リンク
- About state in dbt | dbt Developer Hub
- Defer | dbt Developer Hub
- Manifest JSON file | dbt Developer Hub
- OIDC federation
- Workload Identity Federation
- Customizing CI/CD with custom pipelines | dbt Developer Hub
- dbt Cloudが自動で作成したBigQueryのデータセットのうち、古いデータセットを削除するマクロを運用する - yasuhisa's blog