
なぜBigQuery Editionsのクエリ単位のコストは正確に計算できないのか
BigQuery Editions を利用していると、ふと「このクエリの実行に、本当はいくらかかっているんだろう?」という疑問が頭をよぎることがあります。コスト管理の徹底はデータ基盤を運用する上で重要な責務であり、クエリ単位の正確なコストを把握したいと考えるのは自然なことです。
しかし、クエリの実行ログ(INFORMATION_SCHEMA や監査ログ)から取得できる total_slot_ms (クエリが消費したスロット時間)を基に料金を計算しても、実際の請求額とは通常一致しません。なぜなら、BigQuery Editions のコンピューティング料金は「クエリが消費したリソース量」ではなく、「リソースを確保していた時間」に対して発生するからです。
この記事では、なぜクエリごとの正確な料金計算が難しいのか、その背景にある BigQuery Editions の課金とリソース管理の仕組みを、風音屋社内で交わされた議論をもとに、技術的な観点から深掘りしていきます。
料金計算の前提:BigQuery Editionsの課金単位
まず基本のおさらいとして、BigQuery Editions の料金は、購入した「スロット」というコンピューティングリソースを確保していた時間に基づいて計算されます。課金は秒単位で行われますが、最低でも1分間の利用料金がかかるのが特徴です。
一方で、クエリの実行ログで確認できる total_slot_ms は、あくまで「クエリの処理中に"実際に"稼働したスロットの延べ時間」を示します。これは、課金対象となる「スロットを確保していた時間」とは必ずしも一致しません。
このズレを生む主な要因が次の2つです。
- オートスケーリングのラグ: 設定により、クエリの負荷に応じてスロット数が自動で増減(オートスケール)しますが、その調整にはわずかなタイムラグが伴います。
- スケールダウンウィンドウ: 一度スケールアップしたスロットは、不要になった後も最低60秒間は維持される「スケールダウンウィンドウ」という仕様があります(参考:Use autoscaling reservations)。
たとえば、60秒で終わるクエリを実行した場合、クエリが消費するスロット(total_slot_ms)は60秒分ですが、実際には「スケールアップからクエリ実行開始までの時間」や「クエリ実行完了からスケールダウンまでの時間」についてもスロットを確保している時間として課金されると考えられます。
また、25秒で終わるクエリを実行した場合、total_slot_ms は25秒分ですが、スケールダウンウィンドウが存在するため、課金は最低単位の60秒分発生します。もし直後に別のクエリが実行されれば、維持されていたスロットが効率よく使われることもありますが、実行間隔が空くと発生する「アイドル時間」も課金対象に含まれてしまうのです。
クエリ毎の料金計算を阻む3つの壁
なぜクエリごとの正確な料金計算は難しいのでしょうか。ここからは、その理由となる3つの壁について整理します。
1. 課金時間を左右する「クエリの実行間隔」
前述の通り、BigQuery Editions の課金は「確保されたスロットの時間」に対して発生します。この確保時間は、個々のクエリの実行時間だけでなく、クエリとクエリの間隔の影響を受けます。
例えば「25秒で終わるクエリを2回実行する」ケースを考えます。total_slot_ms の合計は50秒ですが、課金対象となるスロット時間は実行間隔によって次のように変動します。
- 間隔が短い場合: 1回目のクエリで確保されたスロットが、スケールダウンウィンドウ(最低60秒)によって維持されている間に2回目のクエリが実行されれば、2つのクエリはまとめて「1分」の課金で収まる可能性があります。具体的には、間隔が10秒以内であれば1分の課金で収まります。また、10秒を超えたとしても、35秒以内であれば「50秒 + 間隔」の課金で済みます。
- 間隔が長い場合: 1回目のクエリの実行後、スロットが一度解放され、2回目のクエリ実行時に再度確保される、という動きになります。この場合、それぞれのクエリで最低1分の課金が発生し、合計で「2分」の課金が発生します。
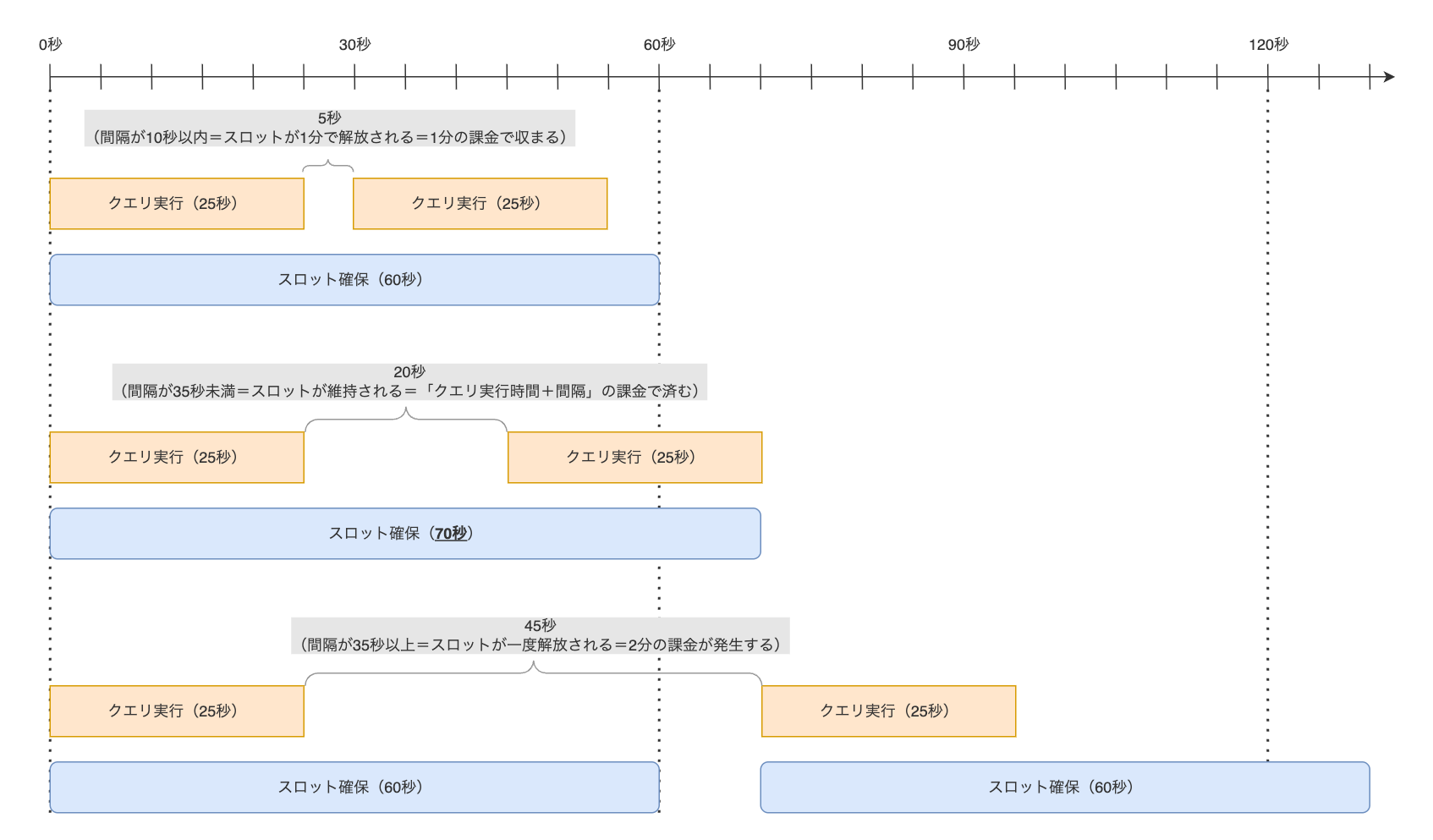
1つ1つのクエリのコストは小さいですが、もし短いクエリが断続的に実行されるような環境であれば、これが積み重なって大きなコストになる可能性も十分にあります。
このように、クエリ単体の情報だけでは課金時間を特定できないのが第一の壁です。
2. 帰属先が不明な「アイドル時間のコスト」
オートスケーリングのタイムラグやスケールダウンウィンドウといった仕様によって、クエリが実行されていないにもかかわらずスロットが確保されている時間、すなわち「アイドル時間」が発生します。この時間も課金対象ですが、このコストをどのクエリに紐づけるべきかという問題が第二の壁です。
スロットは「予約(Reservation)」というリソースプールを、複数のジョブで共有するモデルで管理されています。そのため、あるアイドル時間が「どのクエリの実行を待っていた時間なのか」を特定することは、原理的に困難です。このオーバーヘッド分を合理的に按分する共通のロジックが存在しないため、クエリごとの正確な費用算出が難しくなります。
3. 理想と現実のギャップ「トラッキングIDの不在」
もし、ログに「どのジョブがどのスロット(slot_id)をどれくらいの時間使ったか」という情報が記録されれば、より精度の高い分析が可能になるかもしれません。ジョブに紐付かないスロット時間が併せて記録されれば、アイドル時間も特定しやすくなるでしょう。
しかし、これもまた現実的ではありません。BigQuery のような超大規模な分散システムにおいて、ミリ秒単位で動的に変動する膨大なコンピューティングリソースに対し、一意なトラッキングIDを割り振るとなると、管理が極めて複雑になることが予想されるからです。もちろん、BigQuery が内部でそういった管理をしているのであれば、今後そういったデータが提供されることもあるかもしれませんが、その可能性はあまり高くないのではないかと考えています。
また、既存の INFORMATION_SCHEMA.RESERVATIONS_TIMELINE ビューを使えば、予約単位のスロット確保数を時系列で確認できます。しかし、その集計粒度は1分単位です。ミリ秒単位で実行されるクエリのコストを分析するには、残念ながら情報が粗すぎるのが現状です。
これらの壁があるため、現状ではクエリごとの料金を1円単位で正確に把握することは困難と言えます。
私たちはどう向き合うべきか
では、正確なコストがわからない以上、打つ手はないのでしょうか。そんなことはありません。 私たちの目的は「1円単位で正確なコストを出すこと」ではなく、 「コスト最適化につながるアクションを見つけること」 のはずです。
total_slot_ms は、クエリのコストそのものではなく、「コストの近似値」と考えれば非常に有用です。この値が大きいクエリは、それだけ多くのコンピューティングリソースを消費していることに違いはありません。したがって、total_slot_ms を基準にクエリを並べ、上位のものから順にチューニングしていくのが、効果的で現実的なアプローチと言えるでしょう。
完璧な計測を追い求めるよりも、割り切って改善アクションに繋げる視点が重要です。
まとめ
今回は、BigQuery Editions でクエリごとの料金を正確に計算するのがなぜ難しいのか、その理由を技術的な背景から解説しました。
- BigQuery Editions の課金は「確保したスロットの時間」に対して発生し、「消費したスロット時間 (
total_slot_ms)」とは異なる。 - オートスケーリングの仕様やリソースの共有モデルにより、クエリ単位の正確なコスト計算は原理的に困難である。
total_slot_msはコストの代理変数と捉え、最適化すべきクエリを特定するための指標として活用するのが現実的である。
現在の BigQuery Editions の課金体系は今回説明したような仕組みとなっていますが、total_slot_ms をベースとしたより直感的な課金モデルが実現され、オンデマンド課金と同様の明確なコスト計算ができるようになれば、より多くのユーザにとって使いやすいサービスになるのではないでしょうか。
ぜひ、今後に期待したいと思います。