
BigQuery の「Save results」をモニタリングするための現実的なアプローチ
BigQuery のクエリ結果画面にある「Save results(クエリ結果を保存)」は、クエリ結果を CSV や Google スプレッドシートなどに出力できる非常に便利な機能です。 クエリ結果を手元にダウンロードし、気軽に分析ができるので活用している方も多いと思います。
一方で、データマネジメント、特にガバナンスやセキュリティの観点だと、無秩序にダウンロードが行われるのは好ましくありません。 データセキュリティ向上のためには「誰が、いつ、どのデータを外部に持ち出したのか」を正確に把握できるようにしておきたいです。 一般的に、BigQuery における各種操作は監査ログに記録されますが、「Save results」に関しては、ログを見てもすべての情報を確認できるわけではありません。
そこで、本記事では BigQuery の「Save results」操作を監査ログで追跡する際の限界を明らかにし、その上で現実的なモニタリングを実現するためのアプローチを解説します。
「Save results」とは
機能
「Save results(クエリ結果を保存)」とは、BigQuery で実行したクエリの結果を出力する機能です。 BigQuery のUIでクエリを実行した後、「Save results」をクリックして出力方式を選択すると、クエリ結果をファイルとして実行できます。
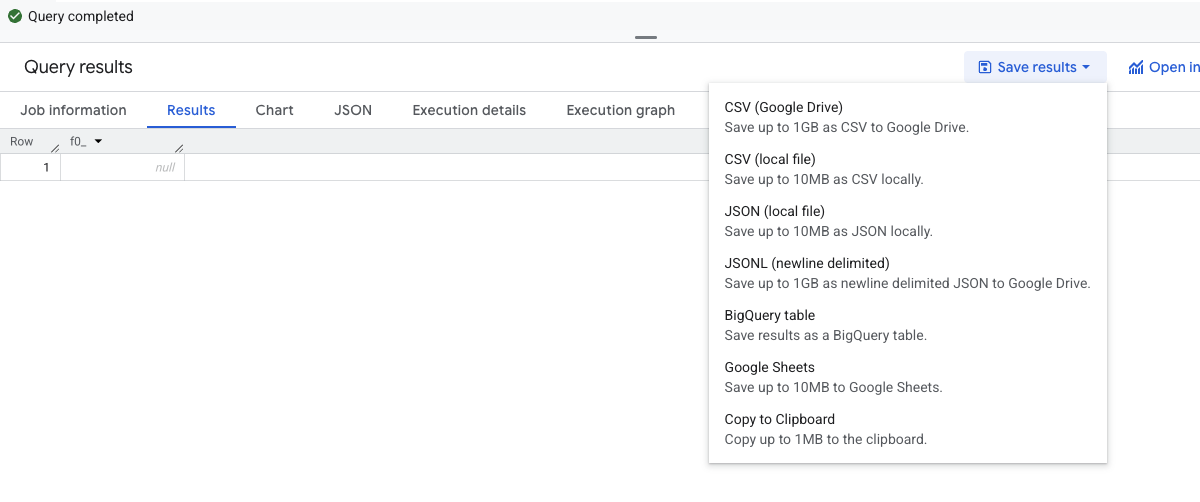
出力先と形式を整理すると、以下のようになります。
| 出力先 | 形式 |
|---|---|
| BigQuery | テーブル |
| Google Drive | CSV |
| Google Drive | JSONL |
| Google Drive | Google Sheets |
| ローカル | CSV |
| ローカル | JSON |
| クリップボード | TSV |
問題点
BigQuery は、多くの企業で重要なデータを格納するデータウェアハウスとして活用されています。 そのため、顧客情報、売上データ、機密性の高いビジネス情報など、適切な管理が必要なデータが含まれていることが多いでしょう。
ところが、Save results を利用すると、こういったデータを BigQuery の外部に持ち出すこともできてしまいます。 たとえば、退職予定者が退職前に CSV ファイルでデータを持ち出してしまう、といったおそれもあります。 そのため、BigQuery の管理者としては、Save results の実行をモニタリングしておきたいです。
そこで、今回はさきほど整理した出力先のうち、外部(Google Drive、ローカル、クリップボード)への出力について、どのように監査ログから情報を得るかについて解説します。
なお、今回の記事では外部への持ち出しにフォーカスするため詳しく説明しませんが、もし必要な場合は Copy (TableCopy) ジョブのログを見れば BigQuery テーブルへの Save results もモニタリング可能です。
モニタリングのためのアプローチ
前提条件
今回のアプローチでは、古い形式の BigQuery 監査ログ(resource.type = "bigquery_resource")を利用します。これは、BigQuery にエクスポートされたテーブルにおいて protopayload_auditlog.servicedata_v1_bigquery フィールドに操作の詳細が記録される形式のものです。
新しい形式(BigQueryAuditMetadata)の監査ログだけに絞っている場合、今回利用するログが期待通りに取得できない可能性がありますのでご注意ください。
1. Extract ジョブのログによる追跡
まず、Google Drive へ CSV または JSONL 形式で結果を保存すると、BigQuery 内部では Extract ジョブが実行されます。
このため、監査ログからこのジョブを特定することで、操作を正確に追跡できます。
具体的には、以下の条件でレコードを取得することにより、「誰が」「いつ」「どのクエリの結果を」「どの Drive パスに」保存したかを正確に把握できます。
- 監査ログから
methodNameがjobservice.insertのものを探す。 - そのうち
servicedata_v1_bigquery.jobInsertResponse.resource.jobConfiguration.extractフィールドが存在するもの(Extractジョブ)を探す。 - さらに、エクスポート元のテーブルのデータセット ID が
_で始まり、テーブル ID がanonで始まるもの(クエリ結果をキャッシュするための一時テーブル)を探す。
2. 複数ログの組み合わせによる推測
一方で、それ以外の出力では、Extract ジョブは実行されません。
これらの操作を特定する直接的なログは存在しないため、複数のログの組み合わせから推測するアプローチを取ります。
UI 上で「Save results」をクリックすると、クエリ結果を取得するために BigQuery のバックエンドでは複数の API が呼び出されます。 その中でも、特に以下の2つの API コールに対応するログが、操作時にほぼ同時に記録される傾向があります。
jobservice.getqueryresultstabledataservice.list
しかし、これらのログは単にクエリを実行した場合や、クエリ結果を UI 上で再表示した場合でも記録されるため、これだけでは「Save results」操作だと断定できません。 そこで、クエリ実行やクエリ結果の再表示といったノイズを除外することで、「Save results」が実行された可能性が高いログのみに絞り込むロジックを組み立てます。
具体的には、以下の条件でレコードを取得することにより、「Save results の可能性が高い操作」を推測します。 なお、以下の条件中のかぎかっこで囲んだ部分はあくまで決め打ちの設定ですので、うまくデータが取れない場合は必要に応じて調整してください。
jobservice.getqueryresultsの「前後3秒以内」に、同一ユーザによってtabledataservice.listのログが記録されているjobservice.getqueryresultsの「前後3秒以内」に、同一ユーザによってjobservice.jobcompleted(ジョブ完了)のログが記録されていないjobservice.getqueryresultsの「前後3秒以内」に、同一ユーザによってjobservice.insert(ジョブ実行)のログが記録されていない- 同一ユーザとは、「
principalEmail、callerIp、callerSuppliedUserAgentが一致するユーザ」のこととする
このロジックで得られるのは、「1. Extract ジョブのログによる追跡」とは異なり、あくまで推測である点に注意が必要です。 また、この方法ではローカル・クリップボード・Sheets のいずれへと出力したのかを区別することはできません。
具体的なクエリ
それでは、これまでご説明したアプローチでデータを抽出するためのクエリ例を紹介します。
このクエリは、Extract ジョブとそれ以外の操作をそれぞれ抽出し、最後に UNION ALL することで、外部へのデータ出力の全体をモニタリングします。
また、QUERY ジョブのデータと組み合わせることで、「どのテーブルを参照しているのか」「どんなクエリを実行したのか」も併せて確認できるようになっています。
WITH
audit_log AS (
SELECT
protopayload_auditlog.authenticationInfo.principalEmail AS user_email,
protopayload_auditlog.requestMetadata.callerIp AS user_ip,
protopayload_auditlog.requestMetadata.callerSuppliedUserAgent AS user_agent,
protopayload_auditlog.methodName AS method_name,
protopayload_auditlog.servicedata_v1_bigquery AS service_data,
`timestamp` AS created_ts,
DATETIME(`timestamp`, 'Asia/Tokyo') AS created_dt_jst
FROM
`<project_id>.<dataset_id>.cloudaudit_googleapis_com_data_access`
WHERE
timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP, INTERVAL 1 DAY)
AND protopayload_auditlog.methodName IN (
'jobservice.insert',
'jobservice.jobcompleted',
'jobservice.getqueryresults',
'tabledataservice.list'
)
AND severity = 'INFO'
),
extract_job AS (
SELECT
user_email,
user_ip,
user_agent,
service_data.jobInsertResponse.resource.jobConfiguration.extract.sourceTable AS source_table,
service_data.jobInsertResponse.resource.jobConfiguration.extract.destinationUris AS destination_uris,
created_dt_jst
FROM
audit_log
WHERE
method_name = 'jobservice.insert'
AND service_data.jobInsertResponse.resource.jobConfiguration.extract.destinationUris IS NOT NULL
),
query_job AS (
SELECT
user_email,
user_ip,
user_agent,
service_data.jobInsertResponse.resource.jobConfiguration.query.query AS query,
service_data.jobInsertResponse.resource.jobStatistics.referencedTables AS referenced_tables,
service_data.jobInsertResponse.resource.jobConfiguration.query.destinationTable AS destination_table,
created_dt_jst
FROM
audit_log
WHERE
method_name = 'jobservice.insert'
AND service_data.jobInsertResponse.resource.jobConfiguration.query.query IS NOT NULL
AND COALESCE(service_data.jobInsertResponse.resource.jobConfiguration.dryRun, FALSE) = FALSE
),
/* CSV/JSON形式でのDriveエクスポート */
save_results_extract_job AS (
SELECT
e.user_email,
CASE
WHEN e.destination_uris[SAFE_OFFSET(0)] LIKE 'gdrive://%csv' THEN 'Google Drive (CSV)'
WHEN e.destination_uris[SAFE_OFFSET(0)] LIKE 'gdrive://%json' THEN 'Google Drive (JSONL)'
ELSE '不明'
END AS save_result_type,
e.destination_uris,
q.query,
q.referenced_tables,
e.created_dt_jst
FROM
extract_job AS e
LEFT OUTER JOIN query_job AS q
ON (
e.source_table.projectId = q.destination_table.projectId
AND e.source_table.datasetId = q.destination_table.datasetId
AND e.source_table.tableId = q.destination_table.tableId
)
WHERE
/* クエリ実行時の一時キャッシュテーブルに絞る */
STARTS_WITH(e.source_table.datasetId, '_')
AND STARTS_WITH(e.source_table.tableId, 'anon')
),
_save_results_others AS (
SELECT
user_email,
method_name,
/*
前後3秒以内に tabledataservice.list の実行があるかどうか
自身が tabledataservice.list でもTRUEになるが、後続のCTEでmethod_nameを絞っているので除外される
*/
LOGICAL_OR(method_name = 'tabledataservice.list')
OVER (
PARTITION BY user_email, user_ip, user_agent
ORDER BY UNIX_MICROS(created_ts) / 1000000
RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING
) AS has_tabledataservice_list,
/*
前後3秒以内に jobservice.jobcompleted の実行があるかどうか
自身が jobservice.jobcompleted でもTRUEになるが、後続のCTEでmethod_nameを絞っているので除外される
*/
LOGICAL_OR(method_name = 'jobservice.jobcompleted')
OVER (
PARTITION BY user_email, user_ip, user_agent
ORDER BY UNIX_MICROS(created_ts) / 1000000
RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING
) AS has_jobservice_jobcompleted,
/*
前後3秒以内に jobservice.insert の実行があるかどうか
自身が jobservice.insert でもTRUEになるが、後続のCTEでmethod_nameを絞っているので除外される
*/
LOGICAL_OR(method_name = 'jobservice.insert')
OVER (
PARTITION BY user_email, user_ip, user_agent
ORDER BY UNIX_MICROS(created_ts) / 1000000
RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING
) AS has_jobservice_insert,
service_data,
created_dt_jst
FROM
audit_log
),
/* ローカル出力・クリップボードコピー・Sheets形式でのDriveエクスポート */
save_results_others AS (
SELECT
user_email,
'ローカル・クリップボード・Drive (Sheets)' AS save_result_type,
CAST(NULL AS ARRAY<STRING>) AS destination_uris,
service_data.jobGetQueryResultsResponse.job.jobConfiguration.query.query AS query,
service_data.jobGetQueryResultsResponse.job.jobStatistics.referencedTables AS referenced_tables,
created_dt_jst
FROM
_save_results_others
WHERE
method_name = 'jobservice.getqueryresults'
/* 前後3秒以内に tabledataservice.list の実行があるものを SAVE RESULTS と判断 */
AND has_tabledataservice_list
/* 前後3秒以内に jobservice.jobcompleted の実行があれば、単なるクエリ実行であると判断 */
AND NOT has_jobservice_jobcompleted
/* 前後3秒以内に jobservice.insert の実行があれば、単なるクエリ実行またはクエリ結果の再表示であると判断 */
AND NOT has_jobservice_insert
),
final AS (
SELECT * FROM save_results_extract_job
UNION ALL
SELECT * FROM save_results_others
)
SELECT * FROM final ORDER BY created_dt_jst;
補足
偽陽性と偽陰性
アプローチ2はあくまで「推測」なので、以下のような誤判定の可能性があります。
- 偽陽性 (False Positive): Save results が実行されていないのに、Save results としてレコードを取得してしまう
- 偽陰性 (False Negative): Save results が実行されたのに、Save results としてレコードが取得できない
ガバナンスの観点では、「余計なログを取得してしまうこと」より「必要なログが抜けてしまうこと」の方が困るので、「偽陽性」より「偽陰性」の方が問題です。
そこで、現状より偽陰性の可能性を下げたい場合は、ロジック内の閾値を調整しましょう。具体的には以下のように調整します。
- tabledataservice.list の探索範囲を前後3秒より長くする
- jobservice.jobcompleted の探索範囲を前後3秒より短くする
- jobservice.insert の探索範囲を前後3秒より短くする
ただし、これはトレードオフです。偽陰性の可能性が下がる一方で、偽陽性の可能性は上がってしまいます。 あまり偽陽性の可能性が上がると、いわゆる「オオカミ少年」状態になってしまい、モニタリングとして意味がなくなってしまうおそれがあるので、バランスを見て調整する必要があります。
Google Workspace 監査ログからのアプローチ
Google Sheets への保存に限定すれば、Google Workspace の監査ログから推測するアプローチも考えられます。
Create イベントで results- から始まるスプレッドシートが作成され、直後に同じ Document ID を持つ Edit イベントが発生したログを探すことで、操作を特定できると考えられます。
ただし、この場合、BigQuery のどのクエリ結果から作成されたかまでは追跡できないため、どのテーブルが参照されたかもわかりません。 アプローチ2のログと照らし合わせて、日時が近い操作から候補となるテーブルを推測することになります。
まとめ
今回は、BigQuery の「Save results」機能の監査について、その限界と現実的なアプローチを解説しました。
監査ログの仕様上、「Save results」のすべての操作を完全に、そして正確に追跡することは困難です。 本記事で紹介したアプローチは、記録されるログのパターンから操作を「推測」するものであり、100%の正確さを保証するものではありません。
しかし、すべてを網羅することはできなくとも、今回紹介したクエリを利用することで、「Save results」によるデータ持ち出しの実態を、何もしない状態に比べてより高い解像度で把握することが可能になります。
保存方法ごとのモニタリング可能性を整理すると、以下のようになります。
- Drive (CSV / JSONL):
Extractジョブとしてログに記録されます。- ログに必要な情報が含まれているので、正確にモニタリングできます。
- その他 (ローカル, Sheets, クリップボード):
- 操作そのものがログに記録されないため、複数のログの組み合わせで推測する必要があります。
- 操作の種類の特定まではできず、誤検知や検知漏れの可能性もあります。
なお、本記事のアプローチを検討するにあたっては、風音屋アドバイザーの na0(@na0fu3y)さんからアイディア及びアドバイスをいただきました。 この場を借りてお礼申し上げます。
本記事が、皆さんのデータマネジメント体制強化の一助となれば幸いです。