
『アジャイルデータモデリング』を学ぶメリットと実践の始め方 〜翻訳者振り返りシリーズ第五弾〜
こんにちは。風音屋 (@kazaneya_PR) でアドバイザーを務めております、打出(@hanon52_)です。普段はピクシブ株式会社で、広告やマーケティング領域のアナリティクスエンジニアとして働いています。
このたび、『アジャイルデータモデリング』(原著: 『Agile Data Warehouse Design』)という翻訳本の出版に、訳者の一人として携わりました。本書は、データ分析のためのデータモデリング手法について書かれた一冊です。
[PR] 2025年2月26日に電子版が発売されました。ぜひお買い求めください。
また、本の要点を30分にまとめたスライドも公開しています。本の内容を詳しく知りたい方は、まずこちらを見ていただくのがオススメです。
30分でわかる『アジャイルデータモデリング』 - Speaker Deck
はじめに
さて、本題に入りましょう。
データ基盤を構築したはいいものの、「データが使いにくい」「分析が進まない」といった声が聞こえてきていませんか? もしかすると、それは「データモデリング」が適切に行われていないからかもしれません。
この記事では、(アナリティクスエンジニアを含む)データエンジニアの皆さんが、『アジャイルデータモデリング』で解説されているデータモデリングを学ぶことで得られるメリットを、「組織」と「個人のキャリア」という2つの視点から掘り下げます。そして、実践の始め方までを具体的に解説します。
- 組織におけるメリット
- 個人のキャリアにおけるメリット
- データモデリングの実践を始める方法
組織におけるメリット:組織にデータ分析を広める
まずは、データモデリングが誰にどのような価値をもたらすのかを考えます。
比較として、適切なデータモデリングが施されていないデータ基盤を想像してみましょう。
データモデリングなきデータ基盤は利用者に苦しみを与える
データ基盤上で適切なデータモデリングが行われていない場合、データ利用者は業務アプリケーションから同期された生データをそのまま分析に使うことになります。これでは、データベースやアプリケーションの仕様に詳しくないと、正しいデータ分析クエリを書くことはできません。
「ユーザー」テーブルを例に考えてみましょう。「user_type = 1」という値があった場合、この「1」の意味を理解するには、バックエンドのコードを読み解く必要があります。これは容易ではありません。
さらに、「ユーザー」テーブルが、実は在籍のユーザーしか含まない「在籍ユーザー」テーブルで、ユーザーが退会した際には、紐づくレコードが「在籍ユーザー」から「退会ユーザー」テーブルに移動するとします。この場合、ユーザーの分析を行う際は、「在籍ユーザー」テーブルをそのまま使うのではなく、「在籍ユーザー」と「退会ユーザー」を結合した「(退会を含む)ユーザー」テーブルを作成し、使用する必要があります。そうしないと、退会ユーザーが集計から漏れてしまうからです。
以下は、登録月別のユーザー数を集計する分析クエリです。
with ユーザー as (
select * from 在籍ユーザー
union all
select * from 退会ユーザー -- 退会ユーザーを加えないと、集計がおかしくなる
)
select
date_trunc(登録日, 月) as 登録月,
count(*) as ユーザー数
from
ユーザー
where
user_type = 1 -- これが「法人ユーザー」を意味することを、SQLだけでは理解できない
group by
登録月
このような状況では、データの利活用はなかなか進みません。データベースに詳しいエンジニアであれば正しくSQLクエリを書けるかもしれませんが、特にSQL初心者にとっては、データ分析のハードルが高くなってしまいます。
思うようにデータを集計できないデータ利用者は、結局、データエンジニアやアプリケーション側のエンジニアにデータ抽出を依頼することになります。そうなると、エンジニアの工数はデータ抽出に割かれ、データ利用者には待ちや手戻りが発生し、プロジェクトは円滑に進まなくなります。データ分析の属人化も解消されません。
データモデリングのあるデータ基盤は利用者に救いを与える
それでは次に、理想的な状況を考えてみましょう。適切なデータモデリングが施されたデータ基盤です。
前処理済みのテーブルが用意されていれば、データ利用者は、データ分析をより簡単に行うことができます。
ここでは、前処理済みテーブルとして「ユーザー」ディメンションを作成します。「user_type = 1」は「user_type_label = "法人"」に置き換えられ、意味が分かりやすくなりました。また、「ユーザー」テーブルには、あらかじめ「退会ユーザー」が含まれています。
create or replace view ユーザー as (
with unioned as (
select * from 在籍ユーザー
union all
select * from 退会ユーザー -- 事前に退会ユーザーを含める
)
select
*,
case user_type
when 0 then "個人"
when 1 then "法人"
when 2 then "その他"
end as user_type_label -- 数値の値をラベルに置き換え
from
unioned
)
これにより、ユーザー数の推移を正しく集計出来るようになりました。
以下は、「ユーザー」テーブルを用いた分析クエリです。
-- 前処理済みテーブル「ユーザー」を参照するため、with 句の定義は不要
select
date_trunc(登録日, 月) as 集計月,
count(*) as ユーザー数
from
ユーザー -- 退会ユーザーはすでに含まれているため、集計ミスを回避できる
where
user_type_label = "法人" -- 法人ユーザーを絞り込んでいることが明確
group by
登録月
分析用に整備されたテーブルを使うことで、データ分析のクエリが簡単になったことがわかります。
データモデリングのあるデータ基盤では、SQL初心者がデータ分析を行うハードルが、ぐっと低くなります。
データ利用者は自分自身で分析が行えるようになるため、データ分析の民主化が進み、プロジェクトはより円滑に進行します。エンジニアの工数も、機能開発やデータ基盤整備により有効活用できるようになります。
個人のキャリアにおけるメリット:時代に左右されない専門性の獲得
ここまでは組織視点でのメリットを見てきましたが、ここからは視点を変えて、データエンジニア個人のキャリアにとってのメリットを考えてみましょう。
データエンジニアが自身の専門性を高める上で『アジャイルデータモデリング』に書かれているデータモデリング技術を学ぶことには、以下のメリットがあります。
- 「データ基盤の3層構造」の一歩先を理解できる
- 最新のツールをより高度に使いこなせるようになる
- 時代に左右されない専門性を身につけることができる
メリット①「データ基盤の3層構造」の一歩先を理解できる
データ基盤は「3層構造」にするとよい、という定説があります。日本では、2018年ごろから提唱され始めたと記憶しています。
| データレイク層 (入力) | データウェアハウス層 (加工) | データマート層 (出力) |
|---|---|---|
| データをそのままコピーする | データソースとユースケースの間をつなぐ ビジネス知識をモデリングする 例)user_type=1は「法人」である |
ユースケースから逆算して、最適な分析用テーブルを提供する |
参考)データ基盤の3分類と進化的データモデリング - 下町柚子黄昏記 by @yuzutas0
入力(データソース)と出力(ユースケース)に最適化するというこの「3層構造」の考え方は、今では多くのデータエンジニアの共通認識となっています。
しかし、入力と出力の間をつなぐ加工(データウェアハウス層)を実装するには、3層構造の理解だけでは不十分です。もう一歩踏み込んだ技術が必要になります。
例えば、先ほど例に挙げた、前処理済みテーブルの作成や、判別が難しいラベルを読みやすくする処理。他にも、履歴の蓄積や、分析ドメイン(例:売上、閲覧など)ごとのテーブル整理など、データ加工には様々なパターンがあります。業界やビジネス、組織構造によっても、必要な加工処理は異なります。
ここで、もし加工処理を適切に実装できないと、処理が複雑になるにつれて、技術的負債が蓄積してしまいます。結果、コードの使い回しが難しくなったり、似たような処理を複数の箇所で書くことになったりします。
すると、新たな分析用テーブルの開発速度が低下したり、同じ指標なのにテーブルごとに微妙に数値がずれて、データ品質が悪化したりしてしまいます。
データモデリング技術を学ぶ意義の1つは、まさにここにあります。『アジャイルデータモデリング』で紹介されている「ディメンショナルモデリング」は、分析用テーブルを作成するための、様々なデータ加工パターンをまとめたものです。これらの知識体系を実践することで、技術的負債を回避しながら、ビジネス知識を効率よくコードに落とし込み、データソースとユースケースの間をつなぐことができるようになります。
参考)別の翻訳者、妹尾さんによるディメンショナルモデリング紹介記事
「とりあえず3層構造に従ったものの、加工の処理をどう整備すればよいのか...」と悩んでいるデータエンジニアの方には、きっとこの本が役に立つはずです。
3層構造の一歩先の世界で必要になる技術を学び、データエンジニアとしての専門性をさらに高めましょう。
メリット② 最新のツールをより高度に使いこなせる
データモデリングや可視化を行うツールは、数多く存在します。BIの領域では Looker や Tableau、Power BI など、データ加工の領域では dbt や Dataform などが代表的です。
実は、これらのツールの裏側には、ディメンショナルモデリングの思想が一貫して存在していると私は見ています。 具体例を挙げると、Looker の "dimension" や "measure" は、まさに「ディメンション」と「ファクト」の概念に対応していますし、Looker の "Explore" は「大福帳テーブル」のような操作性をデータ利用者に提供します。Power BI の公式ガイドには「スター スキーマと Power BI での重要性を理解する」という解説記事があり、dbt の公式ブログにも「Building a Kimball dimensional model with dbt」や「Guide to dimensional modeling」という詳細な解説記事があります。これらの記事では、ディメンショナルモデリングを、それぞれのツールで実装する方法が紹介されています。
データエンジニアがディメンショナルモデリングの知識を身につけていれば、現在主流となっているこれらのツールのパフォーマンスを最大限に引き出し、より上手く使いこなせるようになるでしょう。
さらに、今後新たなツールに乗り換えた際にも、同じ知識を応用することができます。
メリット③ 時代に左右されない専門性を身に付けることができる
データエンジニアリングを取り巻くツールは、移り変わりが非常に激しいです。
例えば、Snowflake の一般提供は2015年、dbt-core v1.0.0 のリリースは2021年12月のことでした。
一方で、データモデリングの基本的な考え方は、昔から変わっていません。
Ralph Kimball が著書『The Data Warehouse Toolkit』でディメンショナルモデリングを提唱したのは1996年です。30年近く前に提唱された思想が、2025年現在も有効なものとして注目されていることは、驚くべきことです。
もちろん、最新のツールを追いかけることも大切です。しかし、流行りのツールの使い方を覚えただけで満足してしまい、ツールを活用して課題解決を行う力や、技術選定を行う力が身につかないと、そのツールの衰退とともに、キャリアが行き詰まってしまう可能性があります。
30年近い時を経ても色褪せない古典を学ぶことで、時代の流れに左右されない専門性を身につけましょう。
参考)アナリティクスエンジニアのキャリアとデータモデリング - Speaker Deck

データモデリングを学ぶことで、データ基盤構築の基礎を固め、最新のツールを使いこなし、そして時代の変化に左右されない専門性を手に入れることができます。
これらは全て、データエンジニアとして着実にステップアップし、市場価値の高い人材へと成長するために不可欠な要素です。
データモデリングの実践を始める方法
ここまで、データモデリングの意義と、『アジャイルデータモデリング』を学ぶメリットについて紹介してきました。
しかし、実務でデータモデリングを始めるとなると、課題もあります。目の前のデータ分析依頼やデータ抽出依頼、機能開発タスクと比べると、データモデリングのタスクは、短期的な価値を説明しづらいため、どうしても後回しにされがちです。
常にリソースがひっ迫している中で、データモデリングを実践するには、少ない工数で素早く価値を実感できる、コスパの良いタスクを見極める必要があります。
そこで、おすすめの方法を2つ紹介します。
方法① データ分析クエリの前処理を共通化する
データ利用者は、どのクエリでも似たような複雑な WITH 句を書いていて、クエリ作成に苦労していませんか?
それは、データ基盤にあるテーブルの形式と、データ分析に必要なテーブルの形式に、大きな隔たりがあることを示唆しているかもしれません。
そのような場合は、クエリから共通部分を抜き出し、ディメンションやファクトを表すビューテーブルを作成しましょう。そうすることで、データ分析の際に、このテーブルを参照するだけで済むようになり、分析用のSQLクエリを簡単に書けるようになります。結果として、データ分析の生産性が向上し、分析結果の洞察や、次の施策立案により多くの時間を割けるようになるでしょう。
以下は、データ分析クエリで繰り返し登場する WITH 句を見つける例です。
-- ここから先を切り出して「ユーザー」ディメンション(dim_users)を作る
with ユーザー as (
select * from 在籍ユーザー
union all
select * from 退会ユーザー
)
-- ここまで
select
date_trunc(登録日, 月) as 集計月,
count(*) as ユーザー数
from
ユーザー
where
user_type = 1
group by
1
方法② 頻繁に参照されるテーブルから着手する
データモデリングの費用対効果を高めるには、分析者1人だけが参照するテーブルを整備するよりも、100人が参照するテーブルを整備した方が、同じコストでより多くの価値を提供できます。
まずは、監査ログなどを活用して、多くの分析者が参照しているテーブルを洗い出しましょう。
参考)データ整備の優先順位付けに役立つテクニック - Speaker Deck
頻繁に参照されているテーブルは、ディメンショナルモデリングにおける「適合ディメンション」である可能性があります。適合ディメンションを整備し、分析者の視点に立って、より使いやすいテーブルへと改良しましょう。

例えば、「ユーザー」テーブルが、プロダクト部門とマーケティング部門の両方のアナリストから頻繁に参照されていると分かったとします。そこで、彼らに「ユーザー」テーブルをどのように分析で活用しているのかヒアリングします。
ヒアリングの結果、プロダクト部門は機能開発、マーケティング部門はマーケティング施策の効果測定のために「ユーザー」テーブルを使っていることがわかりました。また、とくに重要な施策においては、分析のたびに複雑なSQLクエリを記述し、ユーザーの「ロイヤルティ」ごとに施策効果を集計していることも判明しました。
このような場合、適合ディメンション「ユーザー」を新たに作成し、分析に必要な軸を追加します。具体的には、注文履歴からユーザーの「ロイヤルティ」を定義し、どのユーザーが、どの月に、どのロイヤルティだったのかを集計します。そして、それらの列を「ユーザー」ディメンションに結合します。
参考)ファクトからディメンションを作る - Speaker Deck
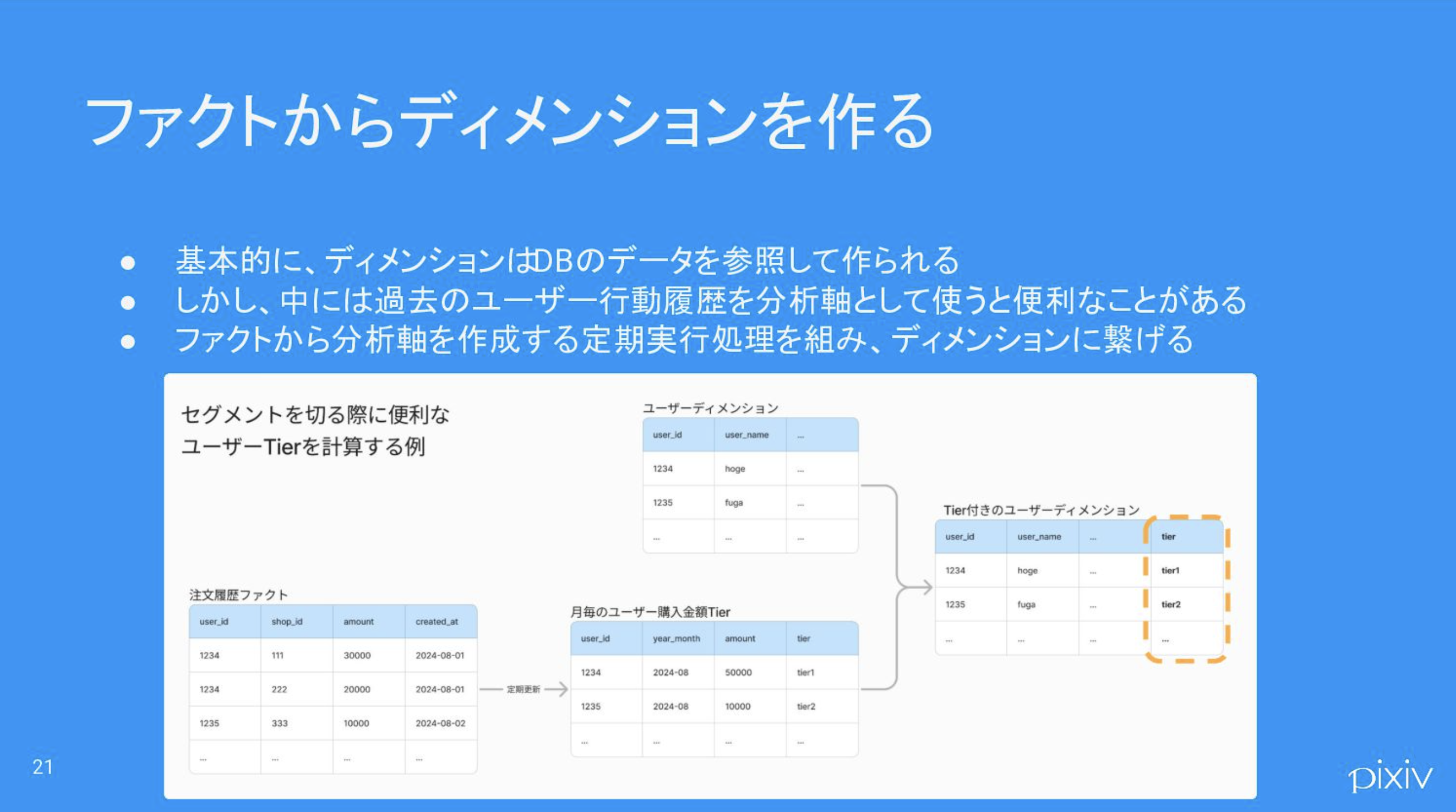
こうすることで、プロダクト部門やマーケティング部門のアナリストは、施策効果を「ロイヤルティ」別に簡単に分析できるようになります。分析の手間を省けることで、より細かな施策についても、気軽にロイヤルティ別の施策効果を分析できるようになるでしょう。
施策の振り返りからより多くを学びを得られるため、次回以降の施策の成功率も高まるはずです。
全く新しい分析軸ではなく、すでに利用実績のある「ロイヤルティ」列に絞って実装を進めている点も重要です。確実に使われることが見込まれる、需要の高いテーブルや列から順番に実装していきましょう。
おわりに
この記事では、データモデリングの意義、『アジャイルデータモデリング』を学ぶメリット、そしてデータモデリングの実践を始めるための具体的な方法について解説しました。
『アジャイルデータモデリング』が、データエンジニアの皆さんの技術研鑽に、少しでも役立つことができれば幸いです。
最後に1つだけ。この本に書かれている理論を実践された方は、ぜひ、そこから得られた知見を公開していただけると嬉しいです。この本の原著は2011年と少し古いため、2025年現在は、当時とは異なる新たな選択肢があるかもしれません。クラウドのデータウェアハウスやモダンデータスタックを活用した、理論と実践の狭間にある議論を、皆さんとできる機会を楽しみにしています。