
INFORMATION_SCHEMAを使用してBigQueryのViewの定義をDataformに移管する
こんにちは、風音屋データエンジニアの妹尾です。
本記事では、INFORMATION_SCHEMAを使用して、BigQueryのViewの定義をDataformに移管する方法についてご紹介いたします。この記事は、BigQuery Advent Calendar 2023 の 21 日目の記事です。
BigQueryを使用していて、データ利用者が増えてくると、以下のような問題が出てくるケースがあるかと思います。
- コンソールでView定義を直接編集するので、ミスが起きやすい
- Viewの変更履歴が残らないので過去時点の集計ロジックも失われてしまう
- 依存関係が分からないので、View定義の変更時の影響調査が大変
- 本番環境と検証環境でViewの定義が違うため、データ加工処理の検証が正しくできない
Dataformを導入すれば、これらの問題を解決することができます。
すでにBigQueryにViewがある状態でDataformを導入する場合、既存のView定義をDataformに移管する工程が必要になります。 特に、BigQuery上に大量のViewがあるケースだと、手動で1つずつ移管することはヒューマンエラーの発生や移管コストの増加につながってしまいます。 こういった場合は、INFORMATION_SCHEMAの情報を使ってDataformの実行ファイルを生成するプログラムを作成することで、移管コストを最低限に抑えましょう。
Dataformとは
Dataformは以下のような機能を提供します。
- データ変換のロジックをソースコードとしてバージョン管理
- データ変換処理のサーバーレス実行
- ウェブブラウザ上での開発作業
Dataformは無料で利用できるサービスです。
Dataformでデータ変換を管理することで、テーブルやViewの依存関係も可視化できるので、データ利用者のデータ理解の助けにもなります。
移管の流れ
移管の流れは以下の通りです。
- Dataformを利用するための準備をする
- INFORMATION_SCHEMAを使用して、移管に必要な情報をCSVファイルとしてエクスポートする
- エクスポートしたCSVファイルを使用して、sqlxファイルを作成する
- リモートリポジトリにプッシュして、DataformのGUIコンソールで確認する
- リリース構成の設定をしてリリースする
- 差分チェックを行う
- 差分チェック後のアクション
作業内容
Dataformを利用するための準備をする
まずは、Dataformを利用する上で必要な準備をしましょう。
詳しい作業内容については記載を割愛しますが、公式ドキュメントに記載の通り実施すれば問題ないです。
INFORMATION_SCHEMAを使用して、移管に必要な情報をCSVファイルとしてエクスポートする
INFORMATION_SCHEMAをクエリするために必要な権限
必要な権限は以下のリンクからご確認ください。
クエリの実装
作成するCSVファイルは以下の2つです。
- プロジェクト内のすべてのテーブルとViewのリスト
- すべてのテーブル・Viewの定義ファイルを作成するために使用する
- Viewが参照するテーブル・Viewのリスト
- Viewのクエリの参照テーブル・Viewをref関数を用いた参照に置換するために使用する
これらを作成するためにクエリのロジックを組んでいきます。
プロジェクト内のすべてのテーブルとViewのリスト
クエリで以下のロジックを実装します。
- INFORMATION_SCHEMA.TABLESから全テーブル・Viewのリストを取得する
- INFORMATION_SCHEMA.VIEWSからview_definitionを取得する
- 1に2を結合し、view_definitionを1のリストにつける
- シャーディングしているテーブルを抽出し集約する(table_name_20231201 -> table_name_*)
出力するCSVファイルのイメージ
| ヘッダー | dataset_name | object_name(テーブルとViewの総称をobjectとしている) | object_type(テーブルとViewの総称をobjectとしている) | sql |
|---|---|---|---|---|
| 格納するデータ | データセット名 | テーブル名 or View名 | テーブル種別 | Viewの定義(テーブルの場合はnull) |
| 参照カラム | INFORMATION_SCHEMA.TABLES.table_schema | INFORMATION_SCHEMA.TABLES.table_name | INFORMATION_SCHEMA.TABLES.table_type | INFORMATION_SCHEMA.VIEWS.view_definition |
| データ例 | kazaneya_dataset | kazaneya_view | VIEW | select * from production_project.kazaneya_dataset.kazaneya_table |
Viewが参照するテーブル・Viewのリスト
クエリで以下のロジックを実装します。
- INFORMATION_SCHEMA.VIEWSからViewのリストを取得する
- View定義からコメントアウトされた箇所を削除する(テーブル参照がコメントアウトされている場合、参照先として抽出してしまわないようにするため)
- 正規表現を使用してView定義から参照先テーブル・Viewを抽出する
ちなみに、参照先テーブル・Viewは、以下のような正規表現を使用して抽出しました。
REGEXP_EXTRACT_ALL(view_definition, "(?i:FROM|JOIN)[\\s\\n]+`?([^`\\s\\n]+)`?")
上記の正規表現の注意点
- CTEも抽出してしまうので、ピリオドを含むテーブル・View名のみ抽出するフィルタをかける必要があります
- 一部だけがバッククォートで囲まれているケース(例:
`project_id`.dataset_id.table_id)は、不適切な形で抽出されてしまいます - 明示されないCROSS JOIN(例:
FROM dataset_id.table_id1, dataset_id.table_id2)は、最初のテーブルのみ抽出されてしまいます
今回2,3に該当するケースは少なかったため特に対応していませんが、必要に応じて修正ください。
出力するCSVファイルのイメージ
| ヘッダー | dest_full_view_name | ref_dataset_name | ref_object_name(テーブルとViewの総称をobjectとしている) | raw_ref_object_name(テーブルとViewの総称をobjectとしている) |
|---|---|---|---|---|
| 格納するデータ | viewの名前 (データセット名.View名) |
参照先のデータセット名 | 参照先のオブジェクト名 | 正規表現で抽出したオブジェクト名をそのまま格納する |
| 参照カラム | CONCAT(INFORMATION_SCHEMA.VIEWS.table_schema, “.”, INFORMATION_SCHEMA.VIEWS.table_name) | 正規表現で抽出した参照先からデータセット名を抽出したもの | 正規表現で抽出した参照先からオブジェクト名を抽出したもの | 正規表現で抽出したオブジェクト名 |
| データ例 | kazaneya_dataset.kazaneya_view | kazaneya_dataset | kazaneya_table | kazaneya_project.kazaneya_dataset.kazaneya_table |
上記2つのリストをCSVファイルとしてエクスポートします。
エクスポートしたCSVファイルを使用して、sqlxファイルを作成する
作成するsqlxファイルについて
DataformでテーブルやViewを定義するには、sqlxという拡張子のついたファイルを作成する必要があります。sqlxファイルにおいて、SQLによる参照をref関数で置き換えることで、テーブルやViewの依存関係を定義することができます。
また、Dataformのsqlxファイルにはtypeという設定項目があります。
今回の移管ではdeclarationとviewという2つのtypeのファイルを作成します。
- declaration:ソースデータの定義ファイル
- view:Viewの定義ファイル
ロジック
前述の通り、今回はconfigのtypeがview、あるいは、declarationのファイルを作成していくことになります。
sqlxファイルを管理するためのディレクトリ構造はお好みでご調整いただくと良い箇所かと思いますが、今回は以下を想定しています。
ちなみに、sqlxファイルはdefinitionsというディレクトリ配下に置かないとコンパイルされません。
└ definitions
└ declaration - データセット名 - テーブル名 ← declarationファイルを格納するディレクトリ
└ transform - データセット名 - テーブル名 ← viewファイルを格納するディレクトリ
前工程で作成したファイルを使用して、sqlxファイルを作成します。
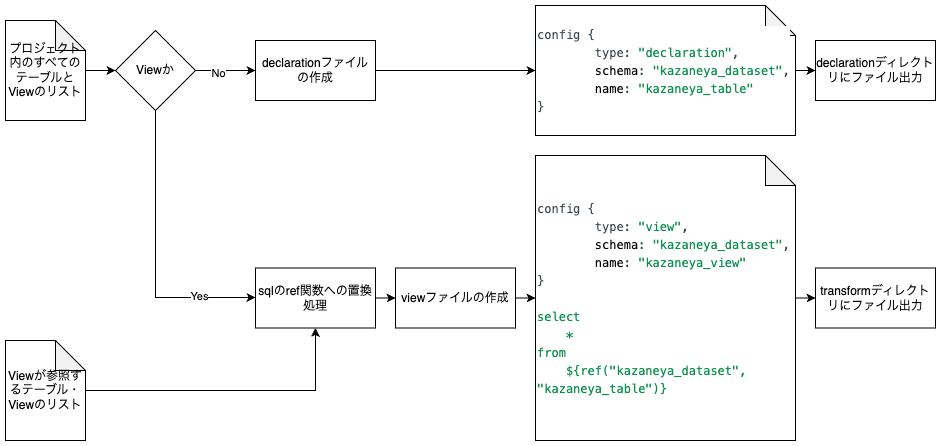
- Viewかどうかは
object_type = “VIEW”で判断します - materialized viewはviewタイプのファイルにconfigで
materialized: trueと設定することによって定義することができます- 上記のフローチャートにはないですが、
object_type = “MATERIALIZED VIEW”の場合は、materialized: trueを追加してください
- 上記のフローチャートにはないですが、
- sqlの置換は、
sqlからraw_ref_object_nameを${ref(“ref_dataset_name”, “ref_object_name”)}にリプレイスする形で実施します - シャーディングしているテーブルは
table_name_YYYYMMDD.sqlxとして、ファイル名にアスタリスクを使用しないようにします- アスタリスクは一般的に特別な意味(ワイルドカードなど)を持つことが多いので、ファイル名として使用することを避けました
ここまで完了したら、Dataformのリポジトリと連携したgitのリポジトリをクローンします。 その後、作成したファイルを含むディレクトリ(definitions配下)を上記のローカルリポジトリにコピーし、作成したファイルをコミットします。
リモートリポジトリにプッシュして、DataformのGUIコンソールで確認する
コミットしたファイルをリモートリポジトリにプッシュします。 その後、Dataformのコンソール上で該当リポジトリからプルして、コンパイルエラーなどがないか確認しましょう。
コンパイルエラーがない場合は、コンソールからCompiled Graphを見れば、Viewの依存関係を確認できます。 コンパイルエラーがある場合は、作成したプログラムの修正を行うか、コンソール上からファイルを修正しましょう。
以下のようなケースですと、コンソール上からファイルを修正する方が良いかと思います。
- Viewが参照しているテーブルが存在しない
- Viewが参照しているデータセットが存在しない
- Viewのクエリにシンタックスエラーがある
上記のようなケースは、メンテナンスされずに放置されているViewを抽出して作成したファイルのコンパイルエラーであることが多いかと思います。 現状、使用されている可能性も低いので、一旦ここではsqlxファイルを削除して、後述する「差分チェック後のアクション」でどのように管理するべきか考えましょう。
リリース構成の設定をしてリリースする
Dataformではリリース構成(release configuration)を使用して、定義したテーブルやViewをBigQueryにリリースすることができます。 いきなりDataformで定義したViewで既存のViewを上書きしてしまうのはリスクが高いため、一定の並行稼働期間を用意してView定義に差分がないかチェックすることをおすすめします。
並行稼働用のリリース構成の例は以下です。
| 項目名 | 設定値 |
|---|---|
| リリースID | 並行稼働用のリリース構成であるとわかる名前 |
| git Commitish | リリース用のブランチ(ワークスペース)名 |
| 頻度 | 任意 |
| スキーマの接尾辞 | dataform |
スキーマの接尾辞をオーバーライドすることで、kazaneya_dataset.kazaneya_viewがkazaneya_dataset_dataform.kazaneya_viewとなるように、既存とは別の新しいViewとしてリリースされます。
上記以外にも、違うプロジェクトにリリースすることや、テーブル名に接頭辞を付けてリリースすることもできます。
差分チェックを行う
並行稼働が開始したら、既存のViewとDataformで作成したViewに差分がないかチェックしましょう。 sqlxファイルの作成と同様に、INFORMATION_SCHEMA.VIEWSを使用することでチェックできます。
例えば、並行稼働しているパイプラインのデータセット名の接尾辞が_dataformの場合だと、kazaneya_dataset.kazaneya_viewとkazaneya_dataset_dataform.kazaneya_viewのview_definitionを比較することでViewのクエリ差分がないか確認できます。
以下の3点をチェックするための差分チェッククエリを作成しましょう。
- View定義に差分があるパターン -> Viewが更新されている
- 既存パイプラインに存在するが、Dataformを使用したパイプラインに存在しないパターン -> Viewが新規作成されている
- Dataformを使用したパイプラインに存在するが、既存パイプラインに存在しないパターン -> Viewが削除されている
差分チェッククエリが作成できたら、BigQueryで差分チェック用のテーブルを作成します。上記3点のどれが該当するかチェックするためのカラムを用意して、どういった変更があったかわかりやすい状態にしておくことをおすすめします。
テーブルが作成できたら差分チェッククエリをスケジュール実行し、作成したテーブルに差分のあるViewをレコードとしてインサートしていくことで記録できます。 定期的に差分チェック用のテーブルを確認し、差分が発生しているViewのリストをGoogleスプレッドシートにまとめていきましょう。
差分チェック後のアクション
差分チェックをしていると、更新が定期的に行われているView(日付指定のフィルタ条件を定期的に変更して使用しているViewなど)や、壊れているView(参照しているテーブルが削除されていてクエリできないViewなど)を発見できるかもしれません。
こういったViewは、Viewの作成者や更新者にヒアリングして、どのように管理するかを決めるとよさそうです。
まず、考えられるViewの管理方法は3つあります。
| 管理方法 | Dataformで管理する | BQコンソールで管理する | 併用する (BQで更新して、dataformでソースデータとして扱う) |
|---|---|---|---|
| メリット | ・バージョン管理できる ・依存関係に基づいてワークフロー実行できる |
更新しやすい | ・更新しやすい ・Dataformでソースデータとして依存関係に組み込むことができる |
| デメリット | 更新する際、GitHubでP.R.を出す必要があり手間がかかる | ・バージョン管理できない ・依存関係に基づいてワークフロー実行ができない |
・バージョン管理できない ・依存関係に基づいてワークフロー実行ができない ・追加する際、GitHubでP.R.を出す必要があり少し手間がかかる |
| マッチするケース | 品質を担保する必要があるView | ・プロトタイプのView ・検証などで一時的に使用したいView |
更新が定期的に行われているView |
全てのViewをバージョン管理して品質担保をしたいというのが、データ整備担当者の本音だと思います。 ただ、検証などで一時的に使用したいViewなども、更新の度にGitHubでP.R.を出す運用にしてしまうと、組織におけるデータ活用のスピード感を損ないかねません。 品質とスピードの両方のバランスをとることが重要です。 バージョン管理したくなったらDataformにViewを移すようデータ利用者に呼びかけたり、Viewの利用状況を監視して定期的にDataformでの管理をデータ利用者に促すような地道な普及活動が必要になるかと思います。
上記を踏まえ、差分チェック後のアクション例です。
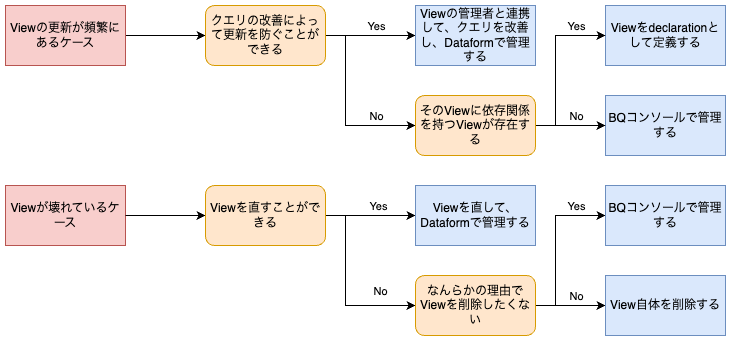
上記のような判断軸で対応方針をViewごとに決めていき、差分チェック用のシート(差分チェックを行うで作成したGoogleスプレッドシート)にViewごとの対応方針を記載していくと良いです。 BigQueryでそのシートを参照する外部テーブルを作成し、以降は「INFORMATION_SCHEMAを使用して、移管に必要な情報をCSVファイルとしてエクスポートする」のクエリで、移管しないと決めたViewが抽出されないようロジックを修正しましょう。そうすることで、不要なsqlxファイルが作成されることを避けることができます。
プログラムを作成して移管することのありがたみ
この方法で移管することで、以下のようなメリットがあります。
- 並行稼働期間中の差分チェックで発見した「更新されたView」「新規作成されたView」「削除されたView」のsqlxファイルの更新、追加、削除が簡単にできる
- テーブルの追加や削除についても検知し、sqlxファイルの追加、削除が簡単にできる
- 手動でファイルを作成してクエリを移植することによるヒューマンエラーの発生を最小限に抑えることができる
また、並行稼働期間中に無理にデータ利用者に働きかけて、テーブルやViewを作成する度にDataform導入の担当チームへの連携をするようお願いしてしまうと、既存業務以外でのコミュニケーションコストの増加や、連絡漏れの発生が懸念されます。 この方法で移管を進めることで、なるべくデータ利用者に負担をかけない形でデータベース内の変更状況を追跡することができます。
おわりに
本記事では、INFORMATION_SCHEMAを使用して、BigQueryのViewの定義をDataformに移管する方法についてご紹介いたしました。
今回はView定義の移管というテーマに絞ってお話ししましたが、Dataformには他にも便利な機能がたくさんあります。 GCP版Dataformは無料で提供されているツールですので、BigQueryを使用されている方は、是非導入を検討してみてはいかがでしょうか。