
Snowparkとは何か? Snowpark for Pythonができること、できないこと
風音屋アドバイザーの渡部徹太郎(@fetarodc) です。
Snowflakeを触っていると「Snowpark」という単語にちょくちょく遭遇することでしょう。 風音屋の社長も、取引先から「Snowparkって何なの?」「Snowparkってどうなの?」と聞かれることが増えているそうです。
このブログではSnowpark for Pythonができること、できないことを具体的に紹介することで、 皆さんのSnowparkに対する漠然としたイメージをシャープにします。
Snowparkとはなにか
Snowparkはプログラミング言語の開発フレームワークです。 プログラミング言語のライブラリとして提供されています。 執筆時点(2023年7月時点)ではJava, Python, Scalaの3つの言語向けにライブラリが提供されています。
当初のSnowflakeは、SQLを扱えるエンジニアのための機能が中心でしたが、 Snowparkが登場してからは、プログラミング言語を扱うエンジニアでもSnowflakeを利用できるようになってきています。
Snowparkの実態を知るためには具体的にできることを紹介したほうがわかりやすいと思うので、 以降はPython向けのSnowpark「Snowpark for Python」を説明することで、皆さんの理解を促進したいと思います。
Snowpark for Pythonとは何か
Python向けのSnowparkライブラリです。
手元の環境で利用する場合には
pip install snowflake-snowpark-python
のようにインストールして
import snowflake.snowpark as snowpark
のようにインポートすれば使えます。
Snowflake上のUDFやストアドプロシジャの中で利用する場合は、実行環境にすでにインストールされているため、いきなりインポートできます。
Snowpark for Pythonでできることは
主に以下の3つです。
- DataFrameという独自クラスを使って、SQLを用いずに、直感的に大規模なデータを操作できる
- UDF(ユーザ定義関数)やストアドプロシジャを簡単に開発することができる
- WebUIのPython Worksheetで簡単に試せる
より詳しい説明はSnowparkの公式マニュアルを参照してください。
DataFrameという独自クラスを使って、SQLを用いずに、直感的に大規模なデータを操作できる
DataFrameというクラスが提供され、そのDataFrameクラスのインスタンスに対してデータを操作するメソッドが提供されています。 例えば、以下のようにメソッドチェーンで行や列を選択できます。
df_product_info = session.table("sample_product_data").filter(col("id") == 1).select(col("name"), col("serial_number"))
df_product_info.show()
-------------------------------
|"NAME" |"SERIAL_NUMBER" |
-------------------------------
|Product 1 |prod-1 |
-------------------------------
他にどんな機能があるかは公式マニュアル「Snowpark PythonでのDataFramesの使用」を参照してください。
DataFrameを用いて記述した内容はSQLに変換されて実行されます。
DataFrameは、遅延評価されるデータセットであり、実行するまでメモリにはロードされないため、大量のデータを処理する場合であってもメモリ溢れなどをおこすことなく処理できます。
注意点として、SnowparkのDataFrameは、pandasのDataFrameとは異なります。 to_pandas() の関数でpandasのデータフレームに変換できます。
UDFやストアドプロシジャを簡単に開発できる
手元のIDE(統合開発環境)などで、UDFやストアドプロシジャを開発し、それをSnowflakeに簡単にデプロイすることができます。 ここで言うデプロイとは、Pythonのコードをzipに固めてSnowflakeのファイルシステムである「Stage」に対してPUTすることを指します。 この作業は手動でやると面倒なのですが、Snowparkを用いると1コマンドでデプロイしてくれます。
また、Snowparkを用いると、Anacondaのライブラリ群を使うことができます。 Anacondaに含まれるPythonパッケージ一覧は、Anacondaのサイトで確認することができます。 UDFやストアドプロシジャで外部のライブラリを使いたいときに役立ちます。
Snowparkを用いて開発したUDFやストアドプロシジャは、Snowflake内にある Built-in Anaconda Packages にアクセス可能な環境で実行してくれます(下図の右下参照)。
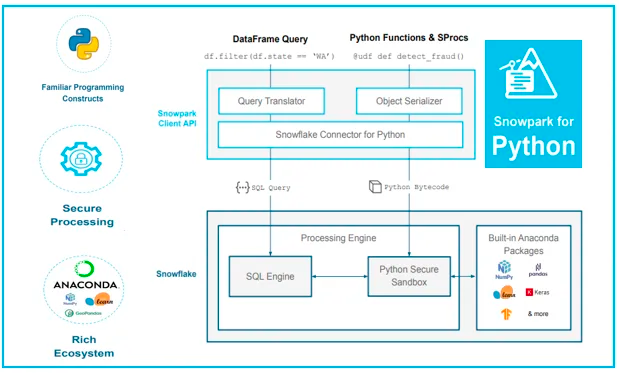
図は "Snowpark for Python- A secured and rich ecosystem." から引用。
WebUIのPython Worksheetで簡単に試せる
Python WorksheetというSnowparkが簡単に試せる画面があります。 執筆時点(2023年7月時点)ではまだプレビュー機能です。
SnowflakeのWebUIにおいて、SQL Worksheetの下にPython Worksheetがあります(下図参照)。
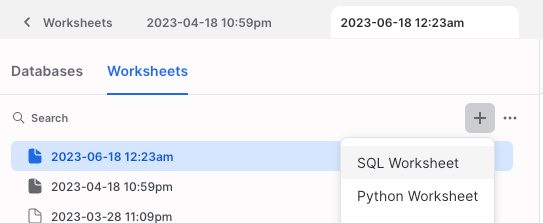
このPython Worksheetを開くと、画面に以下のPythonのコードが表示されるのですが、 コードを見ると分かる通りSnowparkのライブラリがインポートされ使えるようになっています。
# The Snowpark package is required for Python Worksheets.
# You can add more packages by selecting them using the Packages control and then importing them.
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
def main(session: snowpark.Session):
# Your code goes here, inside the "main" handler.
tableName = 'information_schema.packages'
dataframe = session.table(tableName).filter(col("language") == 'python')
# Print a sample of the dataframe to standard output.
dataframe.show()
# Return value will appear in the Results tab.
return dataframe
また、WebUIのPackageのメニューからは、WebUIから使えるAnaconda Packageの一覧が見えますので、必要であればこのパッケージをimportできます。
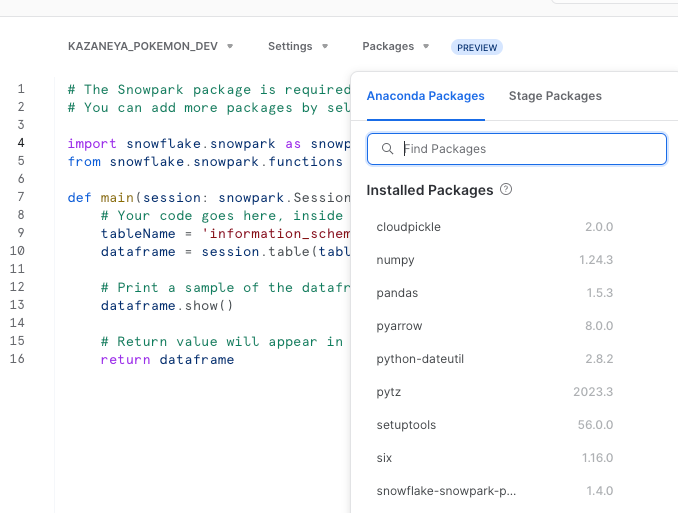
ちなみに、WebUIでは一部のパッケージのみリストされていますが、Anacondaに含まれるPythonパッケージ一覧は、Anacondaのサイトで見ることができます。
Anaconda Package以外のPythonライブラリを用いたい場合は、Stage Packagesのメニューを利用することで、Snowflakeのファイルシステムである「Stage」上にあるファイルを指定して読み込むこともできます。
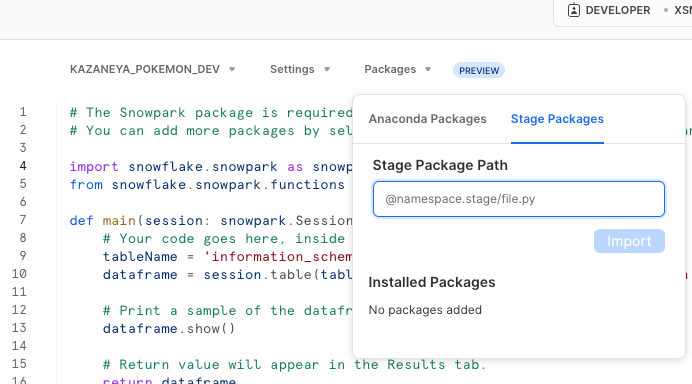
最後に、Python Worksheetの右上のDeployボタンをクリックすると、簡単にプロシージャ化することができます。
Snowpark でできないこと
実行環境は提供しない
私は最初、park=公園という名前からサンドボックス環境を提供するような印象を受けました。 Jupyter Notebookの仮想インスタンスが立ち上がるようなサービスを想像していましたが、そうではありません。 前述の通りSnowparkはライブラリですので、実行環境は別になります。
ではSnowflakeを使って書いたコードはどこで実行するかというと、極論どこでも良いということになります。 AWSのLambdaやGCPのCloud Functionの上でSnowparkライブラリを利用したPythonコードを実行することも可能です。
Snowparkの実行はウェアハウスで行う
もちろん、Snowflake上にも実行環境が用意されており、それはすなわちウェアハウスです。 SnowflakeではSQLを実行するときにウェアハウスを指定しますが、それと同じです。
ただ、SQLを実行する用の標準ウェアハウスとは別に、Snowpark用に最適化されたウェアハウスが存在します。 このウェアハウスはより多くメモリが積んでいるなどの特徴があり、Snowparkを用いたコードが多くのコンピューティングリソースを利用する際に、 このSnowpark用のウェアハウスを利用することで、リソース枯渇を起こすことなくSnowparkのコードを実行することができます。 詳細はこちらの公式ドキュメントを参照してください。
Snowparkの実行をコンテナで行う機能も発表された
先日(2023年6月27日)発表された、Snowpark Container Servicesを使えば、Snowparkをコンテナ上で動かすことも可能です。 ウェアハウスではGPUは利用できませんでしたが、このサービスであればGPUも利用できるため、機械学習のモデル学習などのユースケースでも利用できそうです。
執筆時点ではプライベートプレビュー段階ですが、興味がある方はこちらの公式ブログが参考になるとおもいます。
コラム:Snowparkの名前の由来
ちなみに、今回のブログのレビューを有識者の方にしていただいたのですが、 その時にSnowparkの名前の由来を聞きました。
Snowpark の名前の由来は、Snowflake + Spark だそうです。 Snowflakeの外にApache Sparkを用意して、そこでデータを加工し、Snowflakeに書き戻すことが手間であったため、 Apache SparkをSnowflake内で動かせるようにしたことが、Snowpark登場の背景だそうです。
私はてっきり「雪の公園」かと思っておりました。
まとめ
Snowparkは開発フレームワークであり、実態はプログラミング言語のライブラリです。 従来のSnowflakeではSQLを用いた利用が中心であったのに対し、Snowparkによってプログラミング言語によるデータ処理が可能になりました。 あくまでライブラリであり、Snowpark自体が実行環境を提供しているわけではありません。
Snowpark for Pythonでできることは以下の3つです。
- DataFrameという独自クラスを使って、SQLを用いずに、直感的に大規模なデータを操作できる
- UDF(ユーザ定義関数)やストアドプロシジャを簡単に開発することができる
- WebUIのPython Worksheetで簡単に試せる
シンプルで便利なので、ぜひ皆さんも使ってみてはいかがでしょうか?