
dbt × SQLFluff を GitHub Actions で動かす時の情報漏洩リスクとその対策
兼業データアナリストの星野(@mochigenmai)です。
今回 dbt を利用したデータパイプラインの開発時に、SQLFluff(Linter) を動作させる GitHub Actions を構築しました。 GitHub Actions で SQLFluff を動作させる手順は kazaneya/sqlfluff-dbt-starterkit に公開しているので、よかったら活用してみてください。
この記事では GitHub Actions の環境構築時に発覚した情報漏洩リスクの原因と対策を dbt compile の仕様と合わせて紹介します。
Linter を導入した背景
現在 dbt を利用したデータパイプラインの開発が活発になってきています。データパイプラインは効率的かつ迅速に信頼性の高い分析のために構築します。そのため、データパイプラインの開発にはデータの信頼性を担保する仕組みを導入した方が良いと考えられます。
今回は以下のような点でデータの信頼性を担保できると考え、dbt 開発環境に SQLFluff (Linter) を導入しました。
- バグの原因になるような曖昧な記述を削除する。Wikipedia の Lint に関する記事では「コンパイラではチェックされないが、バグの原因になるような曖昧な記述についても警告される」と述べられている。dbt と BigQuery であれば、BigQuery コンソールでクエリを試した後、dbt への転記ミスによるエラーを防げる可能性がある。
- 複数人での開発時に構文を統一化し、コードレビューの労力を削減する。事前にルールが決まっていれば、構文についての議論を避けることができる。
GitHub Actions の動作と情報漏洩リスク
GitHub Actions の動作は主に以下の 4 ステップです。
- 必要なパッケージのインストール
- sqlfluff
- sqlfluff-templater-dbt
- dbt-bigquery
dbt compile(dbt で jinja のコンパイル)- SQL の Lint
- エラーがある場合は PR にコメント
情報漏洩リスクが発覚したステップは「2. dbt の jinja のコンパイル」です。
このステップでは jinja で記載されている箇所を実行可能な SQL へ変換します。
一見 SQL への変換だけであれば、DWH の接続設定を profiles.yml に記載しなくても動作しそうです。
しかし、動作させようとすると DWH の接続設定をしてくださいというエラーが出てしまいます。
そのエラーに従って本番環境の DWH に対しての接続設定を行うと、GitHub Actions から本番環境のデータにアクセスできる可能性が出てきます。 GitHub Actions から本番環境のデータにアクセスできてしまうことで、情報漏洩などのリスクにつながると考えられます。
当然ながら GitHub Actions で Terraform や CI/CD 処理を動かすようなケースだと、 GitHub から本番インフラ環境にアクセスできるので同じことではあります。 ただ、今回のケースでは「目的」(Lint)に対して「権限」(本番データアクセス)が強すぎるという点が社内のリスクチェックで課題に上がりました。
情報漏洩リスクの対策方法
上記のような情報漏洩リスクへの対策については以下の 2 つの方法が考えられます。調査を進めていく段階で @mashiike さんからアドバイスをいただきました。ありがとうございました。
- 本番権限付与: 本番環境にアクセスできる権限を付与する(アクセスが実際に行われるのは一瞬だけなので許容する)
- ダミー環境用意:
dbt compileのためだけに利用する環境を作成し、その環境に接続する(以降ダミー環境と呼ぶ)
| 方法 | メリット | デメリット |
|---|---|---|
| 1. 本番権限付与 | 設定が簡単 | 一時的でも CI から本番環境にアクセスできる |
| 2. ダミー環境用意 | CI から本番環境にアクセスできない | 設定までが面倒な上、無駄な環境が必要になる |
今回は情報漏洩リスクへの対策なので「2. ダミー環境用意」を採用しました。
最小構成のダミー環境の作成
ダミー環境は dbt compile 以外には利用しないため、作成やメンテナンスのコストをかけたくありません。
そこで最小構成のダミー環境にするため、徐々に構成要素を増やしていきながら dbt compile が動作するかを検証しました。
本番環境を含めた構成図はこのようになります。
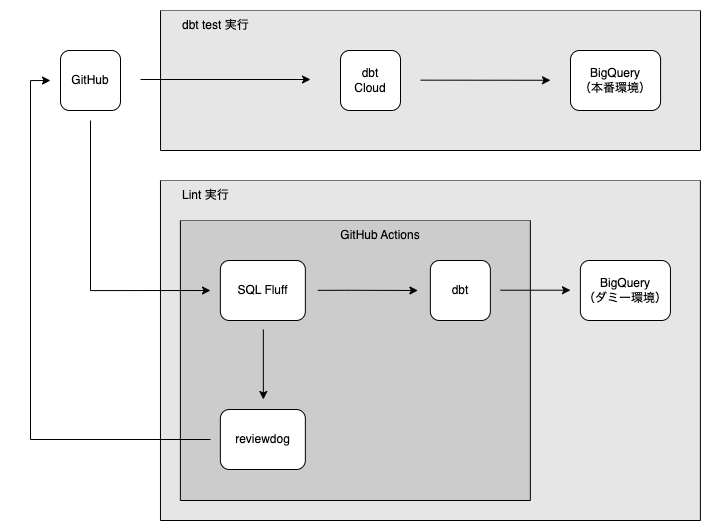
検証1. GCP プロジェクト + サービスアカウントの発行
まずは、ダミーとなる GCP プロジェクトを作成しました。 dbt を DWH に接続するためにはサービスアカウントが必要なので、サービスアカウントの発行も行います。 ここでは、サービスアカウントには権限は何も付与していません。
結果 : BigQuery API を有効にしてくださいというエラーが出る
検証2. GCP プロジェクト + サービスアカウントの発行 + BigQuery API の有効化
検証 1 の構成に加えて、BigQuery API の有効化を行いました。 ここでもサービスアカウントには権限は何も付与していません。
結果 : 動作したため、最小構成は「GCP プロジェクト + サービスアカウントの発行 + BigQuery API の有効化」であることが分かった
dbt-bigquery のロード時に BigQuery に対しての接続確認が行われるためここまでの設定が必要になるようです。この原因となる部分のソースコードを @SassaHero さんに教えていただきました。ありがとうございました。
余談
@syou6162 さんの実体験で SQLFluff を導入したものの DWH に対しての接続設定不足に気が付かず運用してしまっていたことがあったようです。
GitHub Actions で exit status 0 を返すようにしていたため、接続エラーに気づけなかったことが原因と仰っていました。
似たような例として、PullRequest で変更が発生した .sql ファイルのみを Lint 対象とするために、.sql ファイル 1 つずつをループ処理で Lint する場合を考えてみます。
この時、以下のようにループ内に true を記述することが多いと思われます。
あるファイルで Lint エラーが発生した場合でも、そこで処理を止めずに、変更のある .sql ファイル全てを Lint するための記述です。
for file in $(git diff origin/${TARGET_BRANCH} HEAD --diff-filter=AM --name-only -- "*.sql") ; do
sqlfluff lint --dialect bigquery ${file} | true
done
しかし、これでは Lint 以外のエラーが発生しても処理が止まりません。 DWH に対しての接続設定不足に気が付かず運用してしまうことも起こりえるので、このような記述をしている方はお気をつけください。
また、true や exit status 0 を記述していると Lint エラーが発生した場合でも、処理としては成功にチェックがついてしまいます。
true や exit status 0 を記述しないことを推奨します。
変更のある .sql ファイル全部を Lint するには、以下のような処理を入れることで対応できます。
- 途中でエラーが起きたらフラグを立てて処理を続け、最後にエラーを返す
- Lint 結果を吐き出した json ファイルの内容を確認してエラーを返す
※まだ kazaneya/sqlfluff-dbt-starterkit だと未対応ですが、改善していきたいと思っています。
まとめ
今回は dbt を利用したデータパイプライン開発において、Linter を導入することでバグが起きにくい仕組みを構築しました。
dbt の仕様から「GitHub Actions から本番環境のデータにアクセスできる可能性がある」という点で情報漏洩リスクにつながることが分かりました。 少なくとも、 Lint のためだけに本番データへのアクセス権限を付与するというのは、セキュリティ観点から望ましくありません。
情報漏洩リスクの対策方法として「dbt compile のためだけに利用する環境を作成し、その環境に接続する」という選択肢をとりました。
ダミー環境の作成やメンテナンスにコストをかけないために、最小構成のダミー環境を作成しました。
今後 dbt のアップデートで DWH の接続設定を行わないでコンパイルできるようになる可能性も考えられますが、現時点のリスクの認知やその回避方法の参考にしてください。