
ログ欠損が発生した時、データエンジニアは現場でどう対応しているか
風音屋 アドバイザーの “たけっぱ”(@takegue) です。
Webサーバやアプリケーションなどのログが何らかのトラブルで欠損する「ログ欠損」は、データエンジニアが現場でよく遭遇するトラブルです。 しかし本などを見ても、意外と解決方法は載っていません。
そこで風音屋の創業者である “ゆずたそ”(@yuzutas0)さん と、ログ欠損が発生した際、データエンジニアとしてどのような対応をしているかを語り合いました。
※この記事は、YouTube動画「データマネジメント.fm」の第1回目「ログ欠損が発生した際にどういった対応をしているか」 を書き起こし、加筆・修正したものです。
書き起こし・編集:松本香織

この記事で話していること
- 欠損していないデータはない。
- まずは影響範囲を確認 → エスカレーション。
- リトライできるように冪等性を担保しておこう。
- サービスレベルとログ実装のギャップを埋めよう。
欠損していないデータはない
ゆずたそ:たけっぱさんは、現場でログ欠損が発生した時、どういう対応をしていますか?
たけっぱ:そうですね、何から話そうかな。そもそも僕は程度の差こそあれ、「欠損していないデータはない」と思っているんですよ。
ゆずたそ:その心は?
たけっぱ:だって「発生したログがちゃんと取れています」とSLA(※)で100%保証するなんて、無理じゃないですか。
※SLA:Service Level Agreement(サービスレベル合意)の略。当事者間であらかじめ、サービスの品質を明文化し、合意しておくことを指す。
ゆずたそ:そうですね。でも、データを利用する担当者は「ログは全部取れているんでしょ?」と思っちゃいがちですよね。
たけっぱ:そこの非対称性はありますね。
ゆずたそ:ログ欠損が発生するパターンはいくつかあるじゃないですか。 たとえばスマホアプリがタップされた時にログを取るとして、ユーザーが電波が悪いところで利用している場合、システムの処理によっては正確にログが取れず、欠損してしまうとか。
たけっぱ:あとクライアントからデータの転送をする時、ログが送られなくて消えてしまうことがありますよね。 プロトコルにTCPを使っていれば At Least Once(少なくとも1回の到達) が担保され、ログ欠損は生じないですが、UDPの場合は欠損する場合があります。
ゆずたそ:いわゆるパケットロスですね。
たけっぱ:それから、 ログを前処理していることが周知されておらず、問題になるケースもあります。 これは「ログが欠損している」というよりも「ログにフィルターをかけている」という話ですが。
ゆずたそ:ありますね〜。たけっぱさんはこうした問題に対し、現場ではどう対応しています?
まずは影響範囲を確認 → エスカレーション
たけっぱ:実際にログ欠損が起きたとしたら、まず影響範囲を確認します。 めちゃくちゃクリティカルなところなのか、それほどでもないのか。 そして関係者にエスカレーションし、結果次第でどれくらい緊急で対応するか決めます。
ゆずたそ:障害対応で最も重要なのはエスカレーションですからね。 その結果、「一応ログは取っているけど、実はぜんぜん使っていません」と分かったら、そもそも騒ぐ必要はないかもしれない。 では、めちゃくちゃクリティカルな問題だったらどうします?
たけっぱ:デスマーチで確定じゃないですか?(笑) ただ、リトライで対応できる問題はそれで対応するシステムをあらかじめ作っておくことが大事です。 たとえば、ETLパイプラインでアップストリームが止まったとしても、復旧可能な状態にしておくとか。 それがある前提ならば、頑張って復旧させる感じです。
リトライできるように冪等性を担保しておこう
ゆずたそ:DBからデータウェアハウスへの連携に関しては、リトライによる復旧が現実的ですね。 元のデータさえ残っていれば、データの転送や集計は再挑戦できます。
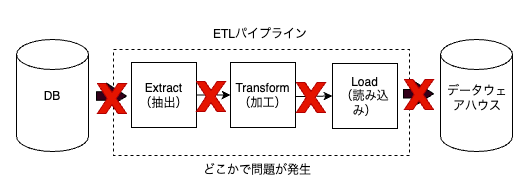
DBからデータウェアハウスに連携する部分でログ欠損が生じたとしてもリトライで復旧が可能
たけっぱ:ですね。ただ、冪等性(べきとうせい)を担保できるように設計しておかないといけません。
ゆずたそ:いつ集計しても同じ結果にならないとダメですね。 今日集計しても、1ヶ月後に集計しても、今日の売上は同じ金額にならないといけない。 集計をやり直す度に金額が変わってしまったらデータを信頼できなくなってしまいます。 ログさえ保存されていれば、あとはテクニックの問題です。
たけっぱ:そう。きちんと設計すれば、冪等性は担保できます。ログさえあれば。 これが「ユーザーが使っているアプリケーションにバグがあってログが送信できませんでした」となると、お手上げだけど。
ゆずたそ:それはお手上げですね、もうどうしようもない。
サービスレベルとログ実装のギャップを埋めよう
たけっぱ:アプリケーションからDBにログを送信する部分では、監視が重要になります。 いかに問題を早く検知し、ロールバックするかが大切です。
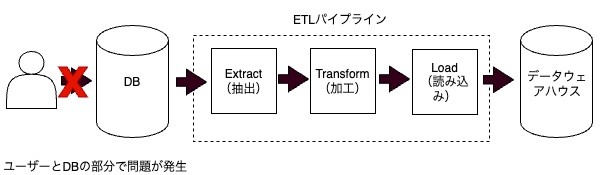
ユーザー側からDBにログが飛ばず、結果としてログ欠損が生じた場合、リトライでは対応ができない、監視による早期の問題検知が重要になる
ゆずたそ:ログ欠損で超慌てる時はそのパターンだと思います。 Google Analyticsで1時間だけログが飛んでいなかったとか。 こういうケースは、もうどうしようもないじゃないですか。
たけっぱ:はいはいはい。どうしようもないですね(笑)。
ゆずたそ:「発生したログがきちんと取れている」という保証が100%はできない中で、どれだけの品質を保てるのか。 そこが重要になってくると個人的には思います。 すごく重要なモニタリングであれば、トランザクションが効くRDBMSで必要なデータを記録するという話になるでしょう。 そこにも障害が起きたら、みんながツラいやつですね。 でも、データマネジメント担当者のところでログ欠損が問題になる時は、サービスレベルとそれを実現する方法がマッチしていないことが多いんだろうなと。
たけっぱ:そのとおり。そこはコントロールしないといけません。
ゆずたそ:ですよね。どういうデータを取っていて、それがどこで使われていて、どれくらいの品質が求められていて ―― そういう期待事項をステークホルダー間ですり合わせることが必要です。 1回ではうまくいかないでしょうから、定期的に、たとえば2週間に1回振り返りの機会を設け、関係者で認識を揃えていく。 そして必要に応じて、モバイルアプリといったプロダクトの実装を改善していく。 Google Analyticsでしか取っていなかったデータをDBでも管理するように変更するとか。 それが本質的な対応なんだろうと思いますね。
たけっぱ:「前もって予防しておく」という考え方のほうが、僕らもラクですからね。
ゆずたそ:健全ですよね。事前にしかるべき品質を決めておく。
本日のまとめ
たけっぱ:でもそうなると、ログ欠損が発生した時、僕らができることはほとんどないんじゃないですか?(笑)
ゆずたそ:元データが残っているならリトライで対応する。 リトライしやすいように元データのコピーを保存したり、処理の冪等性を担保しておく。 元データが残っていないなら、エスカレーション、レポーティング、期待値調整、そしてデータ取得箇所の設計の見直し。 欠損してしまったものはもう、どうしようもないと思っています。
たけっぱ:保存していないデータを復旧することはできませんからね。
ゆずたそ:今日話したことはデータエンジニアからすると当たり前で、よく話題にも上ります。 だけど「どの本を読めば書いてあるの?」と初心者に聞かれたら、たぶん答えられないじゃないですか。
たけっぱ:きょうの話は「SRE(Site Reliability Engineering)」という考え方に基づいていますが、確かに「ログ欠損への対応法」という書籍があるわけではないですね。 ログ欠損は、ゆずたそさんの本でも言及されていなかったと思います。
ゆずたそ:うっ、確かに。まだ書籍化できていないトピックは他にも山程あるんですよ。申し訳ない。
たけっぱ:データエンジニアはさまざまな業種のミックスのようなところがあって、勉強を始めようと思うと、インフラ屋さんや分析者、下手すれば機械学習の勉強もしないといけなくなってきます。 僕らも初心者向けの情報発信をやっていくといいかもしれませんね。
データエンジニア、求む!
風音屋 では教科書に書いていない実践的な課題と日々向き合っています。 ナレッジの体系化や書籍の執筆にも挑戦できる環境です。
データエンジニアを募集中ですので、ぜひカジュアル面談にご応募ください。
また、ジュニア人材向けには「第2新卒が3ヶ月でデータエンジニアに転職できる講座」を提供しています。ぜひご応募ください。
(再掲)
※この記事は、YouTube動画「データマネジメント.fm」の第1回目「ログ欠損が発生した際にどういった対応をしているか」 を書き起こし、加筆・修正したものです。
書き起こし・編集:松本香織